VAE
Auto-Encoding Variational Bayes
전반적 설명
이미지 압축 그리고 다시 생성하는 것
암호 인코딩 후 디코딩하는 과정
이들은 음식 얼리고(인코딩) 다시 해동하기 위해 전자레인지에 돌리는 것(디코딩)과 유사
이때, 전자레인지를 통해 완벽하게 "똑같은" 음식을 해동해 먹는 것은 불가
일종의 노이즈가 들어가기 마련이다.
p(z∣x) --> z --> p(x∣z)
우리가 원하는 과정은 이것이다.
어떤 데이터 x를 넣고 잠재변수 z가 생긴다. (인코딩 - 냉동 )
그리고 그 잠재변수를 통해 다시 x를 뽑아내고 싶은 것이다. (디코딩 - 해동)
그런데 당장 사후분포 p(x) 계산은 매우 어렵다 (복잡한 경우가 다수)
그래서 근사 분포를 이용해 구할 것이다
그런데 이 과정에서 역전파 통해 가중치 업데이트 하지만 랜덤하기에 미분 불가능하다.
하지만 미분 가능해야 하는데??
그래서 재매개화 트릭이 등장
미분 가능하면서 확률 성질(랜덤하니까 다양한 데이터 생성 가능) 놓치지 않는다
대략 이런 과정
1 Introduction
문제: 연속적인 잠재 변수(z) 가진 확률 생성 모델 posterior(사후 확률 분포) 보통 계산이 불가능
→ 근사 추론(approximate inference)으로 해결
→ 기존의 방식(mean-field variational inference) 수식적으로 복잡 or 불가능
해당 논문 SGVB 추정기(Stochastic Gradient Variational Bayes)를 제안
→ 뉴럴넷으로 쉽게 최적화 가능
- 이 아이디어를 바탕으로 만든 알고리즘이 AEVB (Auto-Encoding Variational Bayes)
→ 여기에 뉴럴넷을 사용하면 우리가 알고 있는 VAE (Variational Autoencoder)가 됨
잠재 변수란?
얼굴 사진 - 성별, 감정 상태, 얼굴 각도, 나이
직접 관측할 수는 없지만, 관측된 데이터(표면에 드러난 것)를 생성하는 데 중요한 역할을 하는 ‘숨겨진 변수’
2. Method
잠재변수 z → 데이터 x를 생성하는 확률 모델 p(x, z)
사후확률 p(z∣x) 너무 복잡 대신 q(z∣x)라는 근사 분포로 대체
이때 추론 성능 나타내는 변분 하한(ELBO)을 최적화 가능한 함수로 만들기
이걸 바탕으로 Variational Autoencoder (VAE) 구조 구현
2.1 Problem scenario
우리가 겪는 두 가지 큰 어려움
1. 수학적으로 계산이 불가능 (Intractability)
- 정확한 사후 확률 p(z∣x), 주어진 x의 확률 p(x), 모두 계산 불가능 (적분이 너무 복잡)
2. 데이터가 너무 많음 (Large-scale data)
- 데이터가 너무 많아서 한꺼번에 학습할 수 없음 (batch 최적화 불가)
- MCMC 같은 샘플링 기반 방법은 너무 느림
해결하고자 하는 3가지 문제
| θ 학습 | 파라미터 θ를 최대우도(ML) 또는 최대사후(MAP)로 학습하고 싶음 |
| z 추론 | 주어진 x에 대해 z를 효율적으로 추론하고 싶음 (인코딩) |
| x의 주변 추론 | p(x)추정 → 이미지 복원, 생성 등에 활용 가능 |
그래서... Recognition Model q(z∣x)
- p(z∣x) 직접 계산 불가 -> 근사 모델 q(z∣x) 도입 (Variational Inference)
- 이 모델 **"Probabilistic Encoder"**라고 부름 → x를 받아서 z의 분포(예: 정규분포)를 출력
- 생성 모델 p(x∣z)는 반대로 "Probabilistic Decoder" → z를 받아서 x의 분포를 출력
2.2 Thevariational bound

변분 하한 항을 최적화하려고 하는데...


- φ는 q(z∣x)의 파라미터인데, 여기서 샘플링을 하려면 미분이 어려워짐
- 일반적인 Monte Carlo gradient estimator는 분산이 너무 크고 unstable
그래서 Reparameterization Trick 도입
→ 샘플링을 미분 가능한 방식으로 바꾸는 방법
2.3 SGVB Estimator와 AEVB Algorithm
이 절에서는 ELBO(변분 하한)를 미분 가능한 방식으로 샘플링하여 추정하는 방법을 설명합니다.
→ 이름: SGVB = Stochastic Gradient Variational Bayes Estimator
- 샘플링을 미분 가능한 함수로 바꿈
- 즉, z ~ q(z|x) 대신
→ z = g(ε, x) where ε ~ N(0, 1)
2.4 Reparameterization Trick (핵심 아이디어)

- 이걸 쓰면 샘플링 자체가 미분 가능해짐
- 즉, backpropagation으로 φ에 대해 학습 가능

3. Example: Variational Auto-Encoder

- 왼쪽 항: KL divergence — prior와 q(z|x)의 차이
- 오른쪽 항: 재구성 오차 — 샘플 z로부터 x를 얼마나 잘 복원했는가?
4 Related work
Stochastic Variational Inference (SVI)
최근 주목받고 있는 방법이지만, naive gradient estimator는 분산이 너무 큼
→ VAE는 이를 Reparameterization Trick으로 해결
Wake-Sleep algorithm
recognition model 사용하지만, 두 개의 loss를 번갈아 최적화해야 해서
ELBO처럼 이론적으로 정당화된 objective는 아님
→ VAE는 하나의 통일된 목적함수로 학습됨 (ELBO)
5 Experiments
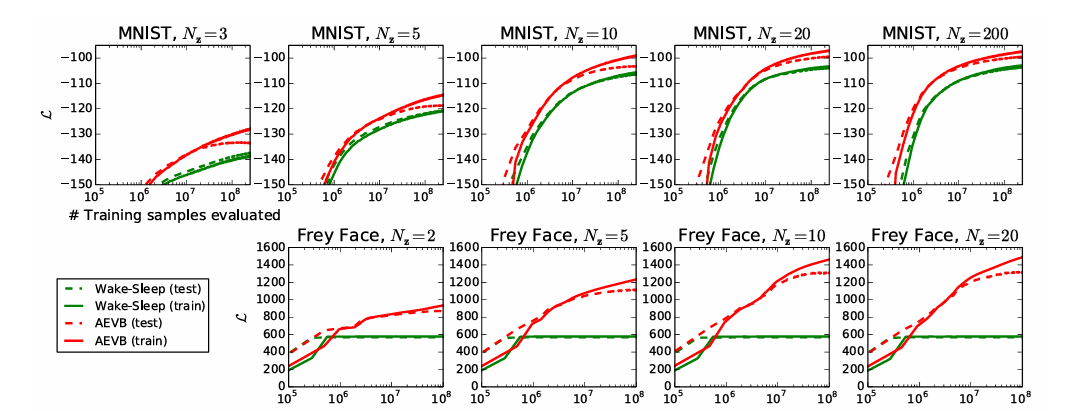
6 Conclusion
SGVB 기반 알고리즘: AEVB (Auto-Encoding VB)
i.i.d. 데이터셋과 연속 잠재변수 구조에서,
SGVB를 활용한 효율적인 인코더-디코더 학습 알고리즘
바로 이 구조가 우리가 알고 있는 Variational Autoencoder (VAE)
7 Future Work
| (i) 딥/계층적 생성 모델 | CNN 등 딥러닝 인코더·디코더를 사용한 구조 확장 |
| (ii) 시계열 모델 | RNN, Dynamic Bayesian Network 등 시간 정보 포함 모델에 SGVB 적용 |
| (iii) 전역 파라미터 추론 | 잠재변수뿐 아니라 모델 파라미터 자체도 변분 추론 대상으로 포함 |
| (iv) 감독 학습 결합 | 레이블 + 잠재변수 → 복잡한 노이즈나 구조적 특징을 학습 가능 |