EfficientNet 이라고 불리는 이유?
너비(Width), 깊이(Depth), 해상도(Resolution)를
고정된 비율로 동시에 확장하는 효율적인 Compound Scaling을 제안했기에
FLOPS는 Floating Point Operations Per Second의 약자
모델이 1초에 수행할 수 있는 부동소수점 연산의 수
1. Introduction
배경: CNN 성능 향상을 위한 스케일링
- 일반적 전략: CNN 모델 크기 확장 → 더 높은 정확도 달성
- 문제점: 모델 확장의 효과적인 원칙 부재
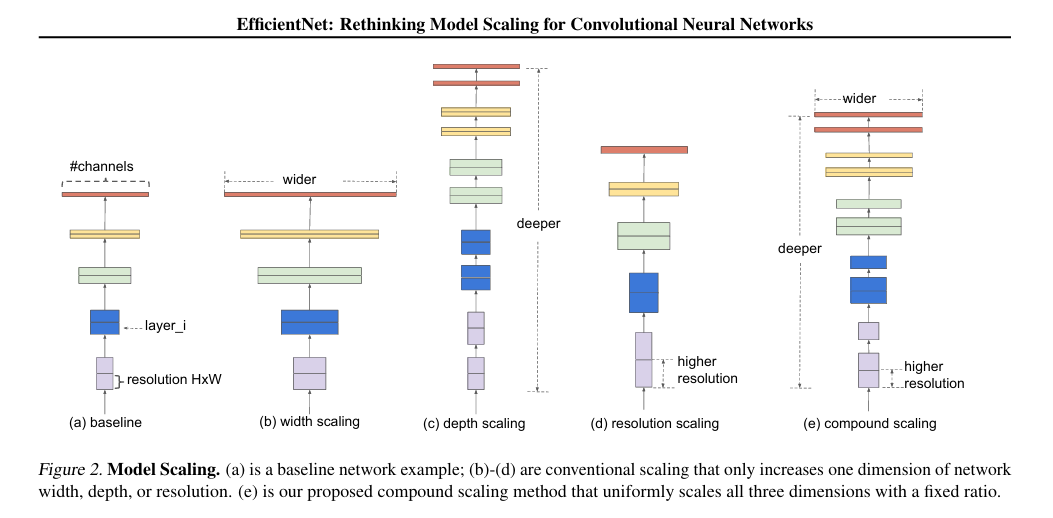
제안된 방법: Compound Scaling (복합 스케일링)
- 핵심 아이디어: 깊이(), 너비(), 해상도() 동시 확장 (고정 비율)
- 예시 (계산량 배 증가 시):
- 깊이: 루트 배
- 너비: 배
- 해상도: 루트 배
- 실제 비율 결정: 소규모 그리드 탐색 활용
- Compound Scaling: 모델의 다양한 차원 균형 있게 확장 → 제한된 자원 내 최대 성능 향상 목표
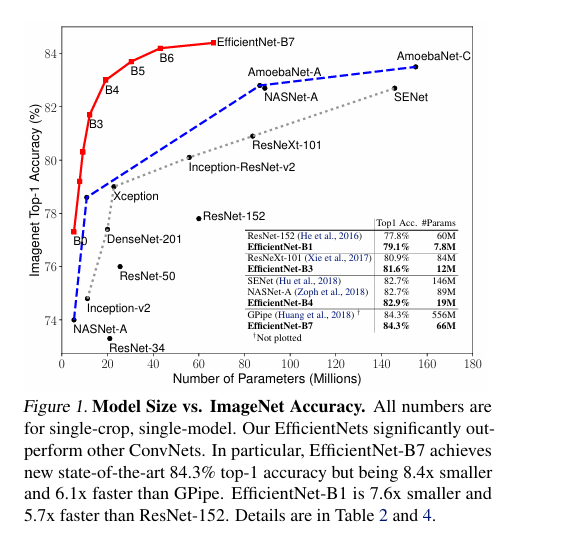
- X축 (가로): 파라미터 수 (모델 크기, Millions = 백만 단위)
- Y축 (세로): ImageNet Top-1 정확도 (%)
- EfficientNet: 같은 정확도 기준 더 작은 모델 & 같은 모델 크기라면 더 높은 정확도 달성
2. Related Work
1. ConvNet 정확도 향상 (Accuracy)
GPU 메모리 한계에 도달했기 때문에, 이제는 모델 효율성이 중요함
2. ConvNet 효율성 개선 (Efficiency)
모델 압축 (Model Compression) 방법 등장
최근에는 Neural Architecture Search (NAS) 기술이 사용됨
-
- 너비, 깊이, 커널 크기 등을 자동으로 튜닝해
- 모바일용 CNN보다 더 뛰어난 효율을 보임
- 단점: 대형 모델에는 NAS 적용이 어려움 (튜닝 비용 ↑, 설계공간 커짐)
3. 모델 스케일링(model scaling) 에 주목
“어떻게 하면 너비, 깊이, 해상도를 효율적이고 효과적으로 조절 가능?” → 명확한 해답 X
Although prior studies have shown that network depth and width are both important for ConvNets’ expressive power, it still remains an open question of how to effectively scale a ConvNet to achieve better efficiency and accuracy.
EfficientNet 기여
너비, 깊이, 해상도 3가지를 동시에, 일정 비율로 키우는 방식 제안
3. Compound Model Scaling
3.1 문제 정의 (Problem Formulation)
CNN의 각 레이어 i는 함수로 표현됨
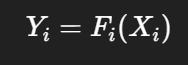
전체 네트워크 NN은 이런 레이어들의 조합
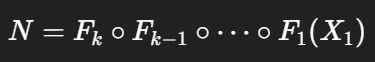
실제 CNN은 여러 스테이지(stage)로 나뉘며 각 스테이지에서 같은 구조를 가진 레이어가 여러 번 반복됨
모델 스케일링이란?

3.2 스케일링 차원 (Scaling Dimensions)
1. Depth (깊이 확장: d)
- 더 깊은 네트워크는 복잡한 특징을 잘 학습함 → 일반화에 강함
- 문제: 기울기 소실(vanishing gradient), 학습 어려움
2. Width (너비 확장: w)
- 채널 수를 늘리면 더 정밀한 특징 추출 가능
- 학습도 비교적 쉬움
- 문제: 너비만 늘리면 상위 추상 개념 파악은 약함
- 너무 넓고 얕은 네트워크는 고수준 특징 파악이 어려움
3. Resolution (해상도 확장: r)
- 더 큰 입력 이미지 사용 → 더 세밀한 정보 포착 가능
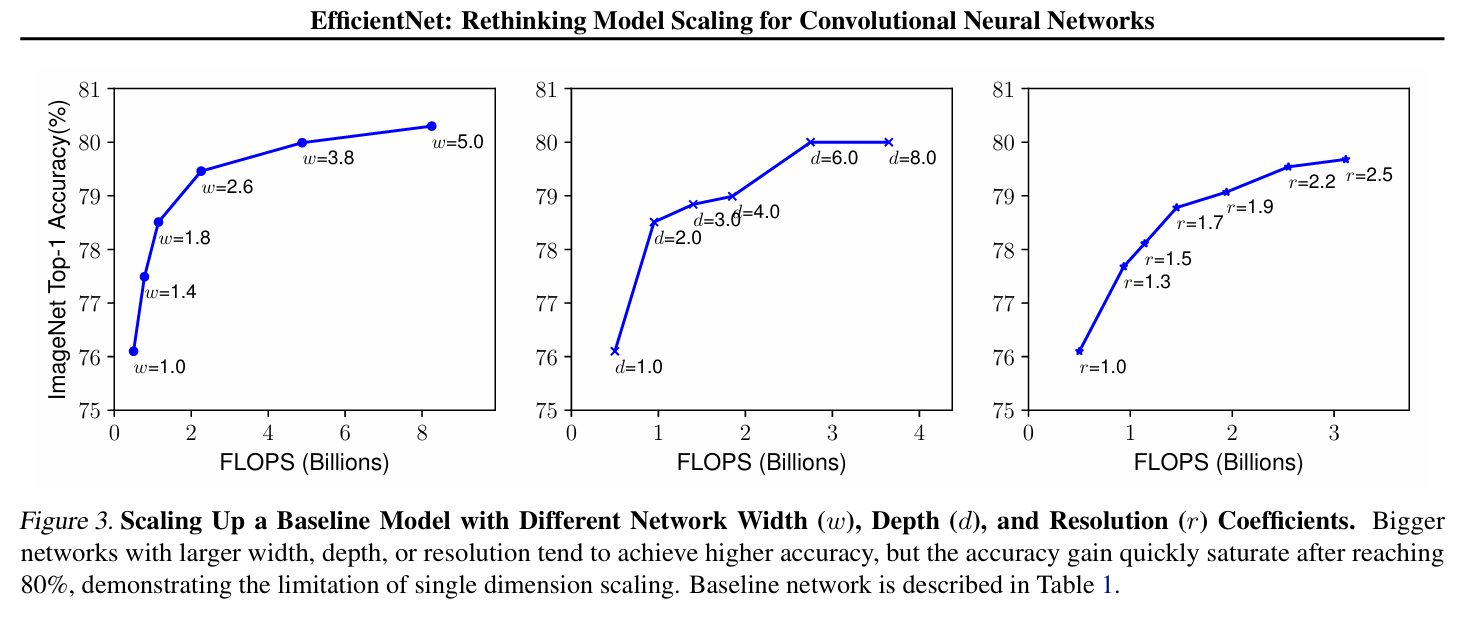
Observation 1– Scaling up any dimension of network width, depth, or resolution improves accuracy,
but the accuracy gain diminishes for bigger models.
"너비(width), 깊이(depth), 해상도(resolution) 중 하나만 키워도 정확도는 올라가지만,
모델이 커질수록 정확도 향상은 점점 줄어든다 (포화 현상 발생)."
즉, 한 방향만 확장하는 건 한계가 있음.
따라서 세 차원을 균형 있게 동시에 확장해야 함 → 다음 절에서 이를 해결하는 compound scaling 제안.
3.3 복합 스케일링 (Compound Scaling) – 핵심 제안
너비(width), 깊이(depth), 해상도(resolution) 서로 독립적 X. 이 때문에 한 가지만 키우는 기존 방식은 성능 향상에 한계가 있음.
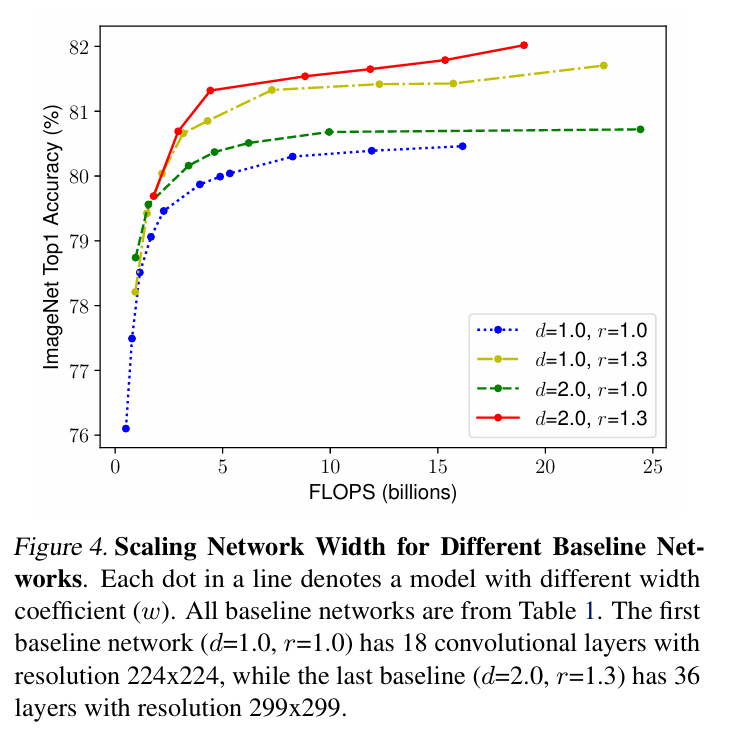
Observation 2– In order to pursue better accuracy and efficiency, it is critical to balance all dimensions of network width, depth, and resolution during ConvNet scaling.
정확도와 효율성 모두를 얻기 위해서는, 너비, 깊이, 해상도를 함께 균형 있게 스케일링해야 한다.
EfficientNet의 제안: Compound Scaling 공식
기존에는 사람 손으로 수동 조절하던 스케일링을,
EfficientNet은 하나의 계수 ϕ (파이)를 통해 자동으로 조정
: 사용 가능한 추가 리소스를 나타내는 스케일링 계수
α,β,γ: 너비, 깊이, 해상도에 대한 가중 비율

4.EfficientNet Architecture
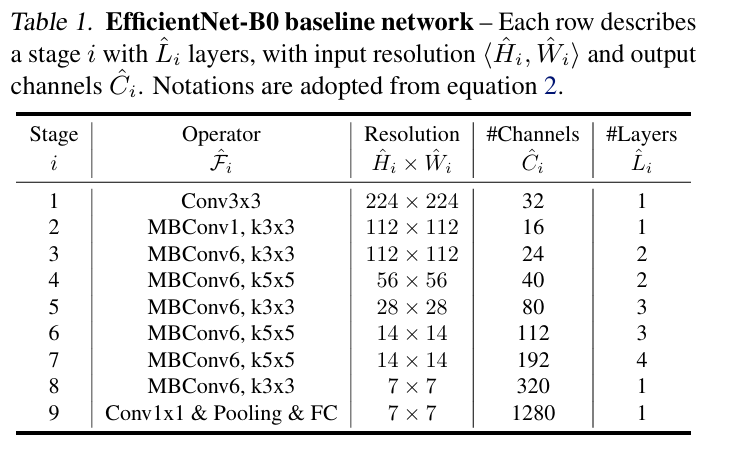
EfficientNet-B0
기반 기술: Neural Architecture Search (NAS)
EfficientNet-B0 → EfficientNet-B1~B7로 확장하는 과정
- STEP 1: scaling 비율(계수) 찾기 (소규모 탐색) - 조건 만족하면서 가장 좋은 조합 탐색
- STEP 2: EfficientNet-B1 ~ B7 생성 - 찾은 를 고정한 채, 스케일 계수 ϕ만 바꾸며 B1 ~ B7 생성
한 번의 NAS → 전체 시리즈 생성 가능 → 확장성, 효율성 매우 우수
5. Experiments
5.1 기존 모델(MobileNet, ResNet) 확장 실험
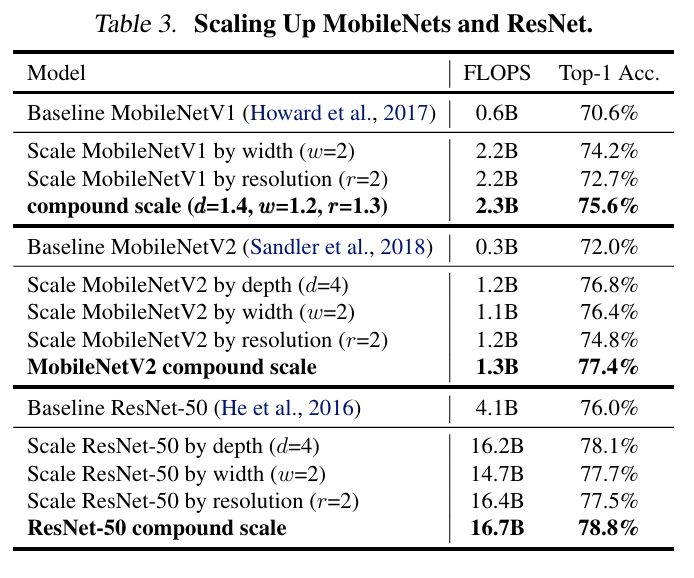
5.2 ImageNet 성능 (EfficientNet vs 기존 모델)
- EfficientNet은 기존 모델보다 최대 8.4배 적은 파라미터, 16배 적은 FLOPS로 동등하거나 더 좋은 정확도
- EfficientNet-B3는 ResNeXt-101보다 정확도가 높고, FLOPS는 18배 작음
5.3 전이학습 실험 (Transfer Learning)
전이학습 과정 : EfficientNet (ImageNet pretrain) ⟶ 다른 소규모 데이터셋 (finetune)
| 기준 모델 | 정확도 | 파라미터 | EfficientNet | 정확도 | 파라미터 |
| NASNet-A (CIFAR-10) | 98.0% | 85M | B0 | 98.1% | 4M |
| GPipe (CIFAR-100) | 91.3% | 556M | B7 | 91.7% | 64M |
| Inception-v4 (Birdsnap) | 81.8% | 41M | B5 | 82.0% | 28M |
- 5개 데이터셋에서 기존 최고 정확도 갱신
- 평균적으로 9.6배 적은 파라미터로 비슷하거나 더 좋은 정확도
6. Discussion
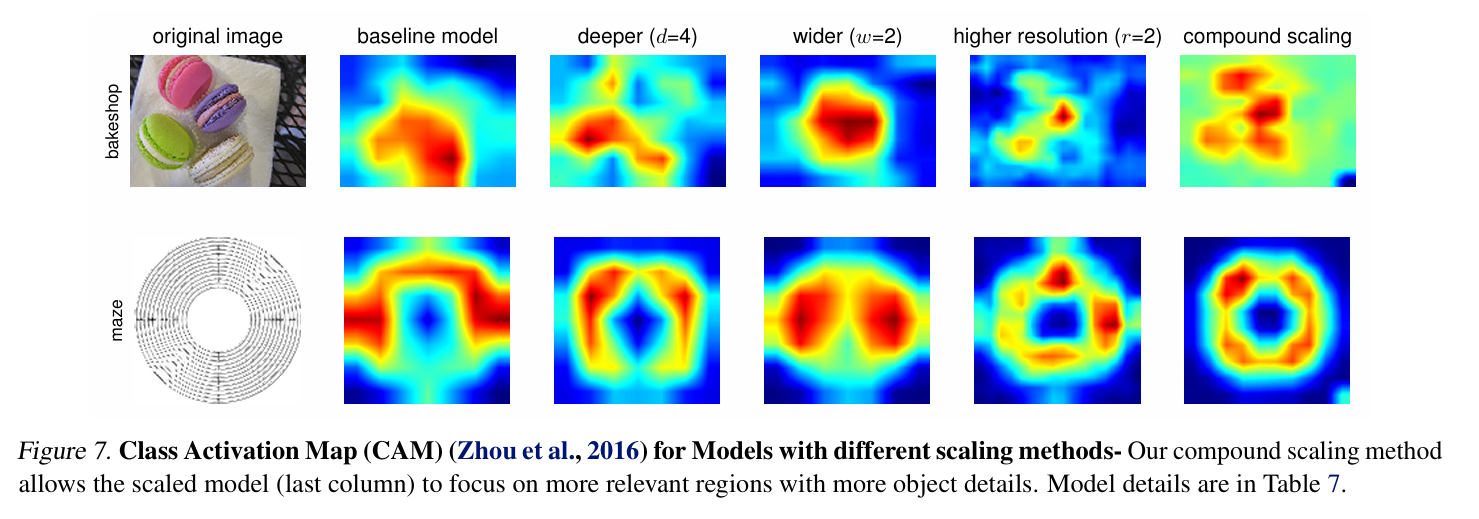
EfficientNet 모델이 잘 작동하는 이유가 아키텍처 혹은 compound scaling 때문? 분리해서 알아보자

모든 방식이 FLOPS가 증가할수록 정확도 향상은 있음
그러나, 복합 스케일링이 단일 스케일링보다 최대 2.5% 더 높은 정확도
즉, 복합 스케일링 방식 자체가 독립적인 성능 향상 요인
7. Conclusion
| 문제 | 기존 ConvNet 확장 방식은 균형 없이 깊이, 너비, 해상도 중 하나만 키움 → 비효율 |
| 해결책 | 너비·깊이·해상도를 비율 기반으로 함께 확장하는 compound scaling 제안 |
| 장점 | 단순하지만 효율적이고 확장성 높은 방식. 리소스에 따라 유연하게 적용 가능 |
| 결과 | EfficientNet은 기존 모델 대비 훨씬 적은 계산량으로 더 높은 정확도 달성 |
| 적용 | ImageNet과 전이학습 데이터셋 모두에서 SOTA 성능 달성 (CIFAR, Pets 등) |
"작고 효율적인 모델도, 균형 있게 확장하면 큰 모델보다 더 잘할 수 있다."