모바일넷?? 모바일 기기에서 잘 돌아가게 만든 네트워크
1. 서론 (Introduction)
- CNN은 2012년 ImageNet 대회 이후 널리 사용
- 일반적으로 더 깊고 복잡한 네트워크가 정확도를 높이지만, 모델 크기와 속도는 비효율적일 수 있음.
- 모바일 및 임베디드 환경에서는 실시간 처리가 필요하므로, 계산량이 적고 효율적인 모델이 필수적.
- 이를 위해 MobileNet을 설계하고, 너비 비율(width multiplier) 및 해상도 비율(resolution multiplier)을 도입하여 모델 경량화.

2. 이전 연구 (Prior Work)
📌 작은 신경망 연구의 발전
최근에는 작고 효율적인 신경망 구축 연구 활발
이러한 연구는 크게 두 가지 접근 방식으로 나눌 수 있음:
사전 학습된 네트워크 압축 - 먼저 큰 모델을 학습시키고, 나중에 작게 압축하는 방식
작은 네트워크 직접 학습 - 애초에 작고 빠른 모델을 직접 설계하고 학습시키는 방식
- 양자화 (Quantization)
→ 32비트 float 대신 8비트 정수 등 더 적은 비트 수로 파라미터를 표현
→ 모델 크기 작아지고 연산도 더 빨라짐 - 해싱 (Hashing)
→ 유사한 가중치 값들을 같은 “버킷”으로 묶어서 저장 (공유)
→ 메모리 절약 효과 있음
📌 MobileNet의 차별점
기존 연구들은 주로 모델 크기 축소에 집중했지만, MobileNet은 지연 시간까지 최적화하는 것을 목표로 함.
깊이별 분리 합성곱을 활용하여 초반 레이어의 연산량을 줄이고 속도를 향상시킴
깊이별 분리 합성곱이란?
깊이별 분리 합성곱은 이를 공간 → 채널 분리해서 두 단계로 나눠 계산

3. MobileNet 아키텍처
3.1 깊이별 분리 컨볼루션 (Depthwise Separable Convolution)
깊이별 컨볼루션 (Depthwise Convolution)
각 채널마다 필터 하나만 적용 (채널 간 결합 없음)
즉, 채널별로 독립적으로 필터링
점별 컨볼루션 (Pointwise Convolution)
1×1 conv로 채널끼리 결합
정보 혼합 역할 수행
--> 계산량을 줄이는 것


3.2 Network Structure and Training

첫 번째 layer만 일반 합성곱(conv) 사용.
나머지 모든 convolution은: Depthwise convolution & Pointwise convolution
모든 layer 뒤에는 BatchNorm + ReLU가 붙음
마지막 fully connected layer는 비선형성 없음, 바로 softmax로 연결됨.
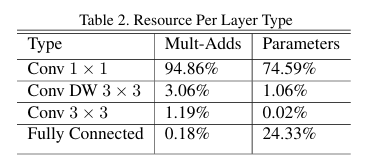
Dense 1×1 convolution에 대부분의 연산이 집중되어 있어서
--> 이건 사실상 dense matrix multiplication (GEMM)
--> 계산량이 단순하지만, 행렬 곱처럼 잘 최적화돼 있음!
im2col 없이도 그냥 원래 데이터 배열에서 바로 행렬 곱하면 되니까, 메모리 낭비 없이 바로 빠르게 계산 가능
3.3 Width Multiplier (α)
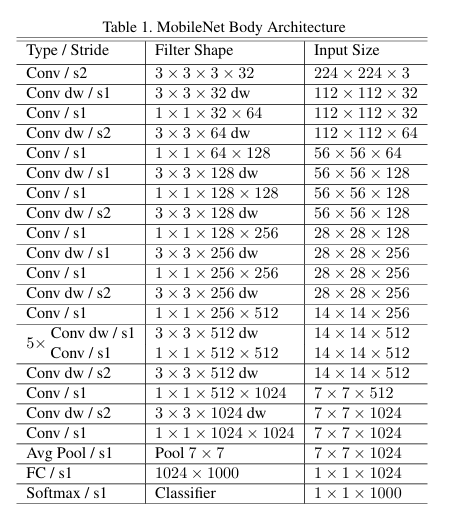
더 얇고 작은 모델 만들기 위해 각 layer의 input/output 채널 수를 비율(α) 만큼 줄임.
한 모델을 여러 크기로 쉽게 변형 가능 --> 속도는 빨라지고 정확도는 일부 손해
왜 유용??
스마트폰에서 얼굴 인식, IoT 카메라에서 사람 감지
--> 너비 비율을 줄여서 연산량을 확 줄이되,"적당히 쓸만한 정확도"를 유지하는 게 핵심
3.4.Resolution Multiplier: Reduced Representation
해상도 비율 (Resolution Multiplier)
입력 이미지의 크기와 모든 레이어의 feature map 크기를 줄이면
➡ 연산량이 크게 줄어든다
대신..
이미지가 저해상도 --> 세밀한 디테일( 엣지나 작은 물체를 구분 )이 사라짐
4. Experiments (실험)
4.1 Model Choices

폭(width) 줄이기 vs 깊이(depth) 줄이기 비교
깊이별 분리 컨볼루션은 연산량과 파라미터 수를 **크게 줄이면서도 정확도 손실은 약 1%**밖에 없음.
폭을 줄인(thinner) MobileNet이 깊이를 줄인(shallow) MobileNet보다 성능이 약 3% 더 좋음.
4.2 Model Shrinking Hyperparameters
Hyperparameters
Width Multiplier : 채널 수 조절
Resolution Multiplier : 입력 해상도 조절

4.3 Fine-Grained Recognition
Stanford Dogs 데이터셋 사용
(비슷하게 생긴 다양한 개 품종을 구분해야 하는 세밀한 분류(fine-grained classification) 문제)
기존 최고 성능(State of the Art, SoTA) 모델에 거의 근접한 정확도
그런데도 모델 크기 엄청 작고, 연산량도 훨씬 적음
MobileNet은 리소스가 적어도, 아주 세밀한 구분 작업에서도 충분히 강력
4.4 Large-Scale Geolocalization
MobileNet은 InceptionV3를 10분의 1로 줄이면서도 유사한 성능 유지
4.5 Face Attributes (지식 증류 활용)
지식 증류
큰 모델(Teacher)**이 먼저 학습 --> 작은 모델(Student)**은 그 큰 모델의 예측을 보고 따라 하면서 학습
결과적으로, 작은 모델도 정답 + 큰 모델의 "감"과 판단 기준까지 학습
여기서도 성능 굿
4.6 Object Detection

4.7 Face Embeddings (Mobile FaceNet)
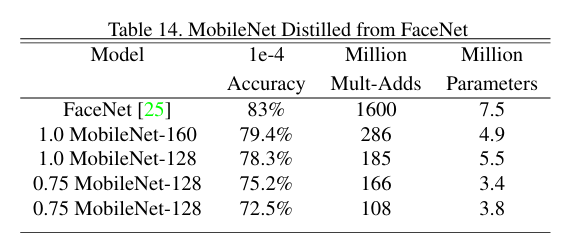
큰 모델(FaceNet)이 해주는 걸 작은 모델(MobileNet)이 지식 증류를 통해 비슷하게 해내도록 학습한 것
--> 나름 성공적
MobileNet은 일종의 타협 모델!!
5. Conclusion
새로운 경량화 CNN 아키텍처 MobileNet을 제안
핵심 구조: Depthwise Separable Convolutions
→ 기존의 Conv보다 연산량과 파라미터 수를 대폭 절감
폭 줄이기 (Width Multiplier) ( 레이어에 있는 채널 수를 줄이는 것 )
+ 해상도 줄이기 (Resolution Multiplier)( 입력 이미지 크기를 작게 사용하는 것)
==> 다양한 성능/속도 trade-off 가능
작아지면 정확도 조금 손해보지만, 지연(latency)과 모델 사이즈는 크게 줄어듦
다양한 모델들과 비교하여, MobileNet은 유사하거나 더 나은 정확도를 보임
ImageNet뿐만 아니라 다양한 실제 응용에도 효과적( Object Detection, Face Recognition, Geo-localization)
Geo-localization
사진이나 센서 데이터를 기반으로, 그게 '지구 상 어디에서 찍힌 건지' 위치를 찾아내는 기술