Bootstrapping Language–Image Pre-training
Bootstrapping 스스로 부츠 다시 신는 것처럼 스스로 모델 향상위해 어떤 일을 했다!!!
그게 뭔데??
Using frozen pre-trained models
계산량 줄이고 안정적
Q-Former
이미지와 텍스트 연결하는 다리!!!
1 Introduction
Vision-language pre-training (VLP) 연구 꾸준히 발전하고 있다
하지만 high computation cost를 발생하는 문제가 있음
off-the-shelf pre-trained된 비전, 언어 모델 사용
→ 이것이 부트스트래핑
→ 효율적인 계산할 것임
off-the-shelf의 의미
If a product can be bought off the shelf, it does not need to be specially made or asked for:
사전 훈련할 때 catastrophic forgetting을 막기 위해 모델 동결한다
In order to leverage pre-trained unimodal models for VLP, it is key to facilitate cross-modal alignment. However, since LLMs have not seen images during their unimodal pre-training, freezing them makes vision-language alignment in particular challenging. In this regard, existing methods (e.g. Frozen (Tsimpoukelli et al., 2021), Flamingo (Alayrac et al., 2022)) resort to an image-to-text generation loss, which we show is insufficient to bridge the modality gap.
이미지가 학습될 때 텍스트가 보지를 못하는 문제
기존 모델들은 image-to-text generation loss 계산하는 것이 방법
근데 충분하지는 않음
그래서 우리는 Querying Transformer (Q-Former) 이것을 제시
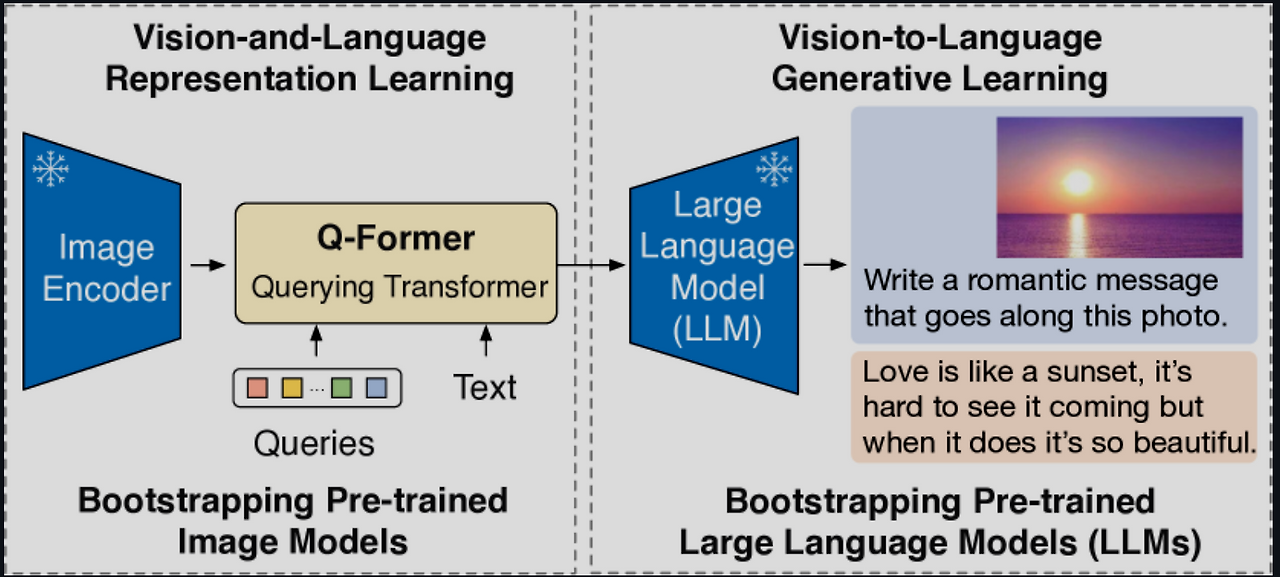
장점 3가지
frozen pre-trained image models 과 language models의 장점 활용
그 두 모델의 차이를 Q-Former를 통해 메운다 (일종의 다리 역할)
representation learning stage 이미지 ----- generative learning stage 텍스트
제로샷에서도 강한 llm
계산량 줄이는 것에서 플라밍고를 능가
fewer trainable parameters
2 Related Work
2.1End-to-end Vision-Language Pre-training
테스크마다 다른 아키텍쳐가 제안됨
대규모 image-text pair datasets 기반으로 end-to-end pre-training을 활용
extremely high computation
inflexible for end-to-end pre-trained models to leverage readily-available unimodal pre-trained models
컴퓨팅 연산이 많이 들고
사전 훈련 유니모달 빠르게 이용하기 위해 end-to-end pre-trained models 유연하지 않고
뭐 이런 문제들 있음
readily
quickly, immediately, willingly, or without any problem:
2.2Modular Vision-Language Pre-training
The key challenge in using a frozen LLM is to align visual features to the text space.
동결 llm 도전 과제는 비주얼 피쳐를 텍스트 공간에 정렬하는 것!!
그래서 이미지 인코더 아웃풋은 LLM의 soft prompt 로 쓰임
Flamingo 는 new cross-attention layers를 삽입했었지..
3 Method
(1) vision-language representation learning stage with a frozen image encoder
(2) vision-to-language generative learning stage with a frozen LLM
1과 2를 잇는 Q-Former
3.1Model Architecture

노란색 박스 Q-Former
Q-Former는 두 개의 트랜스포머 서브 모듈로 구성됨
이것들은 같은 self-attention layers를 공유함
이렇게 하는 이유는??
- 효율적 파라미터 공유하니까
- 통합된 어텐션 패턴 학습 가능
- 이미지 텍스트 대응 잘 됨
쿼리 32개
3.2Bootstrap Vision-Language Representation Learning from a Frozen Image Encoder
태스크마다 다른 마스킹 전략 사용 - 오른쪽 그림 참고
Image-Text Contrastive Learning (ITC)

이미지 텍스트 유사도 구해서 가장 최대로 나온 것 채택

아웃풋 쿼리 이미지 트랜스포머에서 나온 것 Z
텍스트 트랜스포머 t(이것은 [CLS] token의 아웃풋 임베딩)
Since Z contains multiple output embeddings (one from each query),
z 가 여러 개이고 그것들과 t와 유사도를 계산
그중 최대가 되는 것을 고른다
the image encoder → Q-Former stage. 이런 과정에서 정보 누수를 막기 위해 서로 마스킹한다
그래서 그림에서 검정색으로 마스킹된 것 확인 가능
Image-grounded Text Generation (ITG)
텍스트 생성 위해 Q-Former 학습하는 것
Therefore, the queries are forced to extract visual features that capture all the information about the text.
텍스트 정보 잡기 위한 비주얼 피쳐 최대한 뽑아내는 쿼리여야 한다

쿼리Q -> 텍스트 T : 이것은 다 마스킹!!! 안 하면 답을 보여주는 것
텍스트T --> 텍스트T : 자기와 이전 것만 볼 수 있게 그래서 미래 토큰 하나만 마스킹이 되어 있는 것 (삼각행렬 형태)
We also replace the [CLS] token with a new [DEC] token as the first text token to signal the decoding task.
[DEC] 토큰으로 대체 - 디코딩 태스크라는 것을 알리기 위해
Image-Text Matching (ITM)
binary classification이다 매치가 되냐 아니냐
그러니까 bi-directional으로 다 참조해서 결과 내는 것
하드 네거티브 마이닝도 했다고
3.3 Bootstrap Vision-to-Language Generative Learning from a Frozen LLM

output query embeddings Z를 같은 차원 text embedding으로 넣기 위해 fully-connected (FC) layer 사용
projected 쿼리 임배딩이 인풋 텍스트 앞에 prepended 된다 알록달록한 토큰이 사진에서 보이죠?
이것은 soft visual prompts 역할을 하게 되는데
Q-Former에 의해 비주얼 정보 뽑은 것 , pre-trained되고 유용한 정보만 남기게 하기에
This reduces the burden of the LLM to learn vision-language alignment, thus mitigating the catastrophic forgetting problem.
치명적 망각을 완화한다
두 가지 타입의 LLMs
decoder-based LLMs
- Q-Former로부터 나온 정보 가지고 텍스트 생성할 때
encoder-decoder-based LLMs
- 텍스트를 두 개로 나누고
- prefix text : 비주얼 정보랑 같이 llm 인코더의 인풋이 된다
- suffix text는 생성 텍스트 타겟이 되고
3.4Model Pre-training
이런 다양한 이미지 텍스트 데이터 사용
- COCO
- Visual Genome
- CC3M
- CC12M
- SBU
- LAION400M (115 million images)
CapFilt 방법도 도입
- 10개 캡션 생성 + 오리지널 캡션
- 11개 유사도 계산
- 높은 거 1,2 순위 중 랜덤으로 하나 선택
이미지 인코더 사전훈련
마지막 레이어 지우니까 성능 살짝 향상
사전훈련하고 모델 동결
왜? 메모리 사용량 줄이고 안정화 가능
llm 사전 훈련
태스크마다 다르니까 이렇게 2개 사용
OPT models (decoder-only, unsupervised-trained)
FlanT5 models (encoder-decoder, instruction-tuned)
Optimizer 랑 학습률은
Optimizer: AdamW
β₁ = 0.9
β₂ = 0.98
Weight Decay = 0.05
Learning rate:
Peak LR: 1e-4
Schedule: Cosine decay
Warmup: First 2,000 steps = linear warmup
Minimum LR (Stage 2): 5e-5
이미지 증강도 이거 활용
Random resized cropping
Horizontal flipping
4 Experiment

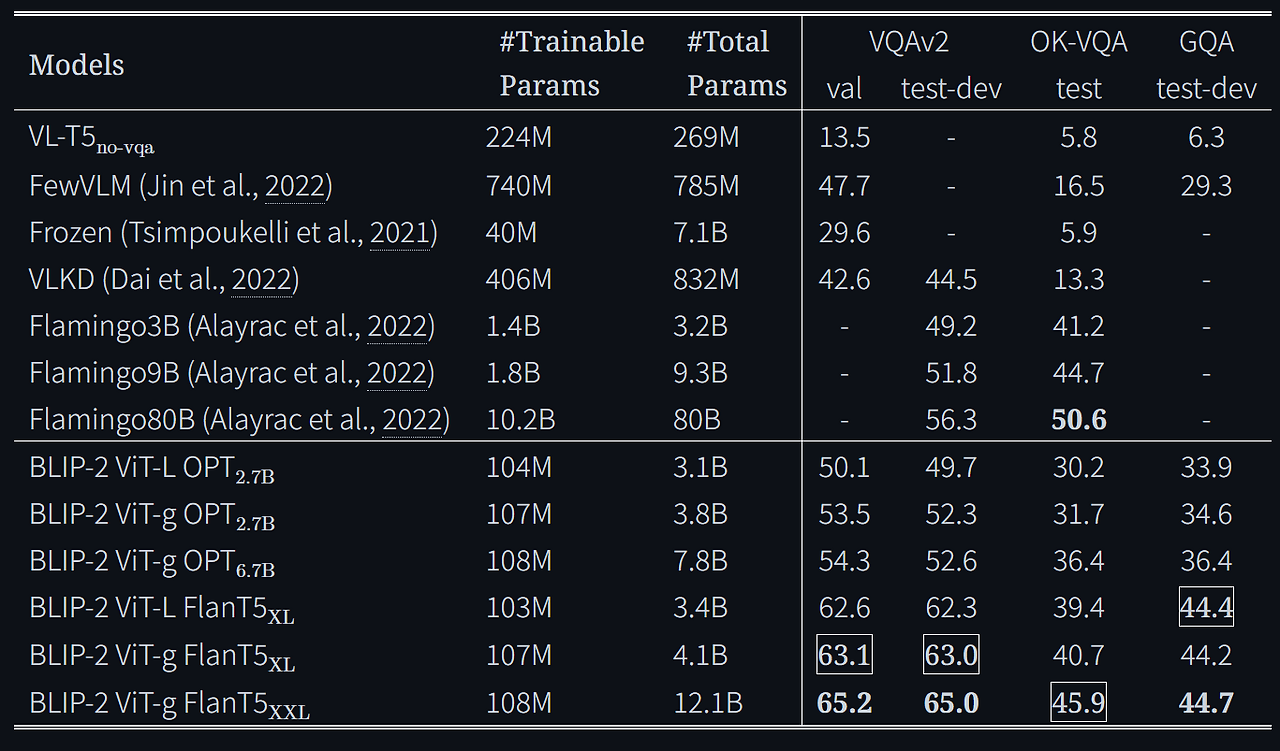
4.1 Instructed Zero-shot Image-to-Text Generation
프롬프트 형식
OPT: "Question: {text} Answer:"
FlanT5: "Question: {text} Short answer:"

Image Captioning에서도 성능 굿
Fine-tuned VQA Comparison에서는 ...
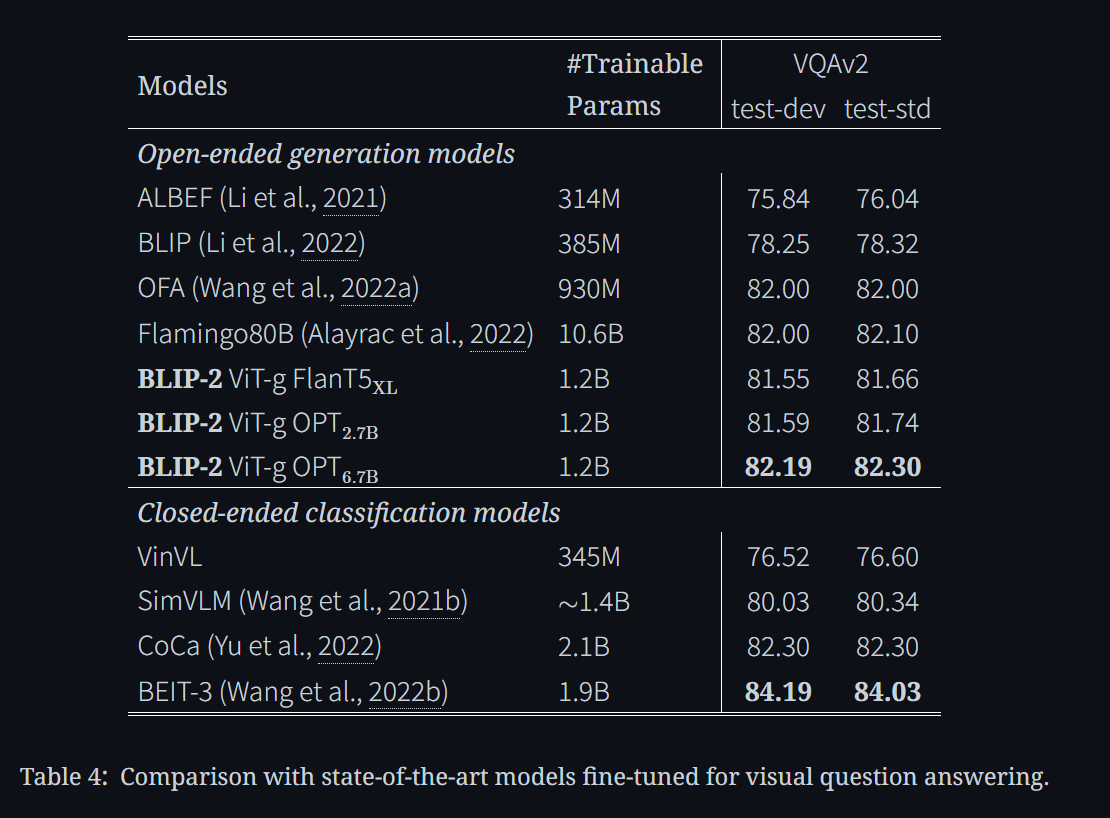
Open-ended generation (e.g., BLIP, Flamingo) vs.
Closed-ended classification (e.g., BEIT-3) 이렇게 비교
Closed-ended classification의 BEIT-3 성능 제일 굿!
BLIP-2 ViT-g + FlanT5 gets 81.7% 이것은 플라밍고랑 비슷한데 파라미터 수가 엄청 적다!!!!
4.2 Image Captioning
"a photo of" LLM 인풋 이렇게 작성
state-of-the-art (SOTA) 달성
4.3 Visual Question Answering (VQA)
SOTA in open-ended generation models 달성
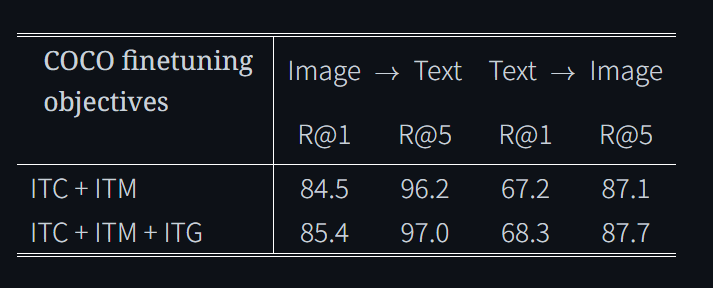
4.4 Image-Text Retrieval
llm 없이도 Image Encoder (ViT-L or ViT-g), Q-Former 가지고도 성능 굿
태스크 이렇게 둘
Image → Text retrieval
Text → Image retrieval
이 둘은 생성이 아니고 해당 텍스트 이미지를 찾는 것
5 Limitation
in-context learning하는 것에서는 성능 향상 발견 못함
사전훈련 데이터셋이 샘플마다 single image-text pair 만 포함해서 그렇다
The same observation is also reported in the Flamingo paper, which uses a close-sourced interleaved image and text dataset (M3W) with multiple image-text pairs per sequence. We aim to create a similar dataset in future work.
플라밍고는 달랐다 샌드위치처럼( interleaved ) 넣었지
이전 llm 부정적인 점 상속 받기도 함
6 Conclusion
frozen pre-trained image encoders 와 LLMs 장점 잘 활용했다
multimodal conversational AI agent 로 가는 길을 열었다!!