BLIP
Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation
부트스트랩이란?
신발에 있는 끈 같은 것
영어에서도 pull oneself up by the bootstraps 라는 표현은 도움 없이 스스로 상황을 개선하는 것(혼자 부트스트랩 올려 신발 신기!!!)
여기서는 모델 자체가 도움 없이 캡션을 만드는 것을 부트스트랩핑 한다고 한 것!


요약
기존 비전 언어 모델은 완전 무결한 데이터가 필요했음
잡음 많은 데이터에도 강건한 모델 만들고 싶다...
BLIP = Bootstrapping + Vision-Language Pre-training
1. Image-Text Contrastive Learning (ITC)
2. Image-Text Matching (ITM) - 하드 네거티브도 추출해서
3. Image-Conditioned Language Modeling (LM)
Bootstrapping
captioning model 통해서 깔끔한 이미지 설명 생성
self-improvement process이기에 Bootstrapping 이라고 하는 것
Vision Transformer (ViT)와 Transformer 사용
1 Introduction
기존 문제점
encoder-decoder models 은 image-text retrieval tasks에서 그닥 성능이 좋지 못함
웹 데이터 잡음이 많음
그래서 BLIP 등장
Multimodal mixture of Encoder-Decoder (MED)
멀티 태스크 사전 학습에 효과적, 전이 학습에도 유연하다
Captioning and Filtering (CapFilt):
노이즈가 많은 웹 데이터도 사용 가능하게
captioner 와 filter 로 구성
2 Related Work

2.1Vision-language Pre-training
웹 데이터 노이즈 여전히 큰 문제
데이터 효과적 사용 가능한 CapFilt 제안한다
모델이 두 태스크를 할 수 있는가가 가장 큰 문제
이해 기반 태스크(예 image-text retrieval) 와 생성 기반 태스크(예 image captioning)
그래서 하나가 아닌 여러 멀티모달을 사용하는 것으로 구성
2.2Knowledge Distillation
자기 증류 이미지 분류에서 탁월
captioner 가 의미가 담긴 캡션을 생성하고 filter는 노이지한 캡션을 제거하면서 증류한다
2.3Data Augmentation
NLP에서는 그렇게 흔하지 않다
이 논문에서는 vision-language tasks를 위한 인위적인 캡션을 생성한 것 이용
3 Method
3.1Model Architecture
visual transformer 사용해서 이미지 쪼개서 인풋으로
[CLS] token과 함께 인코딩
이해와 생성 태스크 위해 multimodal mixture of encoder-decoder (MED) 제안
(1) Unimodal encoder
텍스트와 이미지 분리해서 인코딩
[CLS] token는 텍스트 데이터 앞에 삽입
(2) Image-grounded text encoder
텍스트를 이미지 정보와 함께 읽는 것
Cross-Attention (CA): 이것을 통해 텍스트에 이미지적 정보를 넣는 것
[Encode] Token이란?
[cls] 토큰 같이 image-text pair의 의미 요약한 것
(3) Image-grounded text decoder
[Decode] 토큰도 마찬가지
인코더는 이해 Bi-directional self-attention
모든 방향으로 보게
디코더는 생성 Causal (uni-directional) self-attention
3.2Pre-training Objectives
학습 목표 → 로스 함수 최소화
Image-Text Contrastive Loss (ITC)
Unimodal Encoders에서 진행
이미지와 텍스트 같은 임베딩 차원에 있게 하려고 하는 것
similarity로 계산
Image-Text Matching Loss (ITM)
Image-grounded Text Encoder에서 진행
binary classifier이다
둘이 매치되면 1 아니면 0
hard negative mining해서 헛갈리게 학습도 가능
Language Modeling Loss (LM)
Image-grounded Text Decoder에서 진행
Image + a [Decode] token. 인풋으로 이렇게 넣으면
그러면 캡션을 gpt처럼 생성하는 것
cross-entropy loss를 사용해 비교
3.3CapFilt
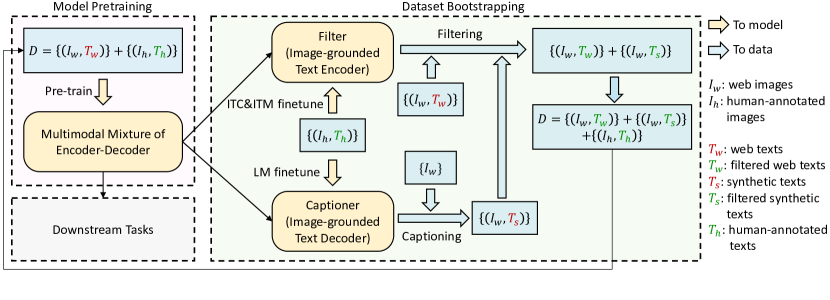
텍스트 코퍼스 질 높이는 CapFilt 제안
CapFilt in MED = mixture of encoder-decoder
Captioner
텍스트 디코더에서 사용
Language Modeling (LM) loss 사용
웹 이미지마다 인위적인 캡션 생성
Filter
text encoder에서 사용
ITC + ITM loss 사용
Original web text T_w 와 Synthetic caption T_s 비교
맞지 않는다면 그 캡션은 버린다
4 Experiments and Discussions
Implementation Setup
Framework: PyTorch
Hardware: Two 16-GPU nodes
Optimizer: AdamW
Weight decay: 0.5
학습 데이터
| 구분 | 데이터셋 이름 | 특징 |
| 사람 작성 | COCO, Visual Genome | 고품질 이미지-텍스트 캡션 |
| 웹 기반 | Conceptual Captions, Conceptual 12M, SBU Captions | 웹에서 자동 수집된 noisy 데이터 |
| 추가 실험용 | LAION (115M 이미지) | 훨씬 더 큰 규모의 noisy 웹 데이터 |


4.2 Effect of CapFilt
| CapFilt 구성 | Captioner + Filter |
| 개별 성능 | 각자 써도 향상됨 |
| 조합 효과 | 함께 쓰면 성능 극대화 |
| 확장성 | 데이터와 모델이 커질수록 효과 증가 |
4.3 Diversity is Key for Synthetic Captions
CapFilt에서 Nucleus Sampling 사용
| Beam Search | - 가장 확률 높은 문장을 탐색 (결정적)- "안전하고 일반적인" 문장 생성 | 캡션은 깔끔하지만 새로운 정보 부족 |
| Nucleus Sampling | - 무작위성 있음 (확률 상위 90% 내에서 선택)- 다양하고 예측 불가능한 문장 생성 | 성능 더 좋음 (비록 noise는 더 많음) |
창의적인 문장 생성 가능
4.4Parameter Sharing and Decoupling
| 사전학습 (Pre-training) | 텍스트 인코더 & 디코더는 SA 제외 전체 공유 | 성능 ↑, 파라미터 ↓, 효율 ↑ |
| CapFilt 파인튜닝 | Captioner & Filter는 개별적으로 finetune | 성능 ↑, 필터링 성능 유지 |
| CapFilt에서 공유 시 | Filter가 자기 출력을 잘 못 걸러서 bias 발생 | 성능 ↓, 노이즈 제거 능력 ↓ |
- 공유된 파라미터로 인해, captioner가 생성한 noisy한 캡션조차도 filter가 잘못된 판단을 덜 하게 됨
5 Comparison with State-of-the-arts
BLIP가 여러 비전-언어(V+L) 작업에서 얼마나 강력하고 범용적인 성능을 보이는지를 보여주는 장
이미지-텍스트 검색 (Image-Text Retrieval)
BLIP는 CapFilt를 사용한 사전학습 덕분에 검색 정확도에서 SOTA를 초과함
이미지 캡셔닝 (Image Captioning)
CapFilt + Nucleus sampling을 통해 생성된 캡션을 학습에 사용하니, 표현 다양성이 높고 성능도 향상됨
VQA (Visual Question Answering)
BLIP는 미세조정 없이도 VQA 데이터셋에서 강력한 성능을 보임
Zero-shot 전이 능력 (Generalization)
BLIP는 CapFilt 덕분에 noisy한 데이터로 훈련되지 않아, 다른 도메인에도 잘 일반화됨
Ablation Study (구성요소 분석)
CapFilt + Nucleus sampling + ViT-L 조합이 최적
6 Additional Ablation Study
CapFilt과의 향상은 긴 훈련 시간 때문이 아니다!
CapFilt 데이터셋으로 학습할 때, 기존에 사전학습된 모델을 이어서 학습하는 게 더 좋은가?
아니다 오히려 새 모델을 처음부터 CapFilt 데이터셋으로 학습하는 게 더 좋음
왜??
지식 증류(knowledge distillation)에서처럼
학생 모델은 교사 모델의 가중치를 그대로 사용하면 오히려 편향(bias) 생김
7 Conclusion
- CapFilt로 부트스트래핑된 새로운 데이터셋으로 사전학습
- 다양한 synthetic 캡션을 추가하고, 노이즈 캡션은 제거함
앞으로...
- 여러 번에 걸친 부트스트래핑 반복
→ 점점 더 나은 데이터셋을 만들어가며 품질 개선 - 이미지당 다수의 캡션 생성
→ 더 풍부하고 다양한 학습 데이터 확보 - 여러 Captioner와 Filter를 앙상블하여 CapFilt 강화
→ 모델 다양성과 안정성 확보