이미지를 받아서 텍스트 내보내는 모델!
CLIP = Contrastive Language–Image Pretraining
쌍을 맞추어 이미지 텍스트를 한번에 사전 학습!!! 그래서 CLIP
1. Introduction and Motivating Work
1. NLP의 혁명적 변화
- raw text에서 직접 학습하는 pre-training 방법 --> NLP 혁명적으로 변화
- 자기회귀(autoregressive)나 마스크드 언어 모델링 같은 task-agnostic( 특정 태스크에 구애받지 않는 ) 목표함수 --> compute, 모델 용량, 데이터 규모에서 여러 차수만큼 확장 --> 성능 향상
2. "Text-to-text" 패러다임의 중요성
- "text-to-text" 방식 핵심
- 이를 통해 task-agnostic 아키텍처가 전용 출력 헤드나 데이터셋별 맞춤화 없이도 zero-shot 전이 가능
3. 웹 스케일 텍스트
- GPT-3 같은 대표적 시스템들이 거의 dataset-specific 학습 데이터 없이도 전용 모델들과 경쟁할 수 있는 성능을 보임
- 힘들인 것보다 훨씬 괜찮다!!
These results suggest that the aggregate supervision acces sible to modern pre-training methods within web-scale col lections of text surpasses that of high-quality crowd-labeled NLP datasets.
4. 컴퓨터 비전의 현실과 질문 제기
- 반면 컴퓨터 비전에서는 여전히 ImageNet 같은 크라우드 라벨링 데이터셋에서 pre-training하는 것이 표준
- "웹 텍스트에서 직접 학습하는 확장 가능한 pre-training 방법이 컴퓨터 비전에서도 유사한 돌파구를 가져올 수 있을까?"
그래서 그 뒤로는 연구 역사에 대해서 이야기
기존 연구 한계점
1. 성능이 그닥 좋지 않다
2. 약한 지도 학습(Weak Supervision)의 절충안
3. 자연어 지도 학습의 제약
- 표현력 한계: 자연어가 표현할 수 있는 훨씬 더 넓은 시각적 개념들을 활용하지 못함
- 동적 출력 부족: 정적 softmax 분류기 사용으로 zero-shot 능력 제한
CLIP의 차별점과 기여
1. 스케일의 차이
- 기존 연구들은 수십만 이미지로 며칠간 학습 // Weak supervision 연구들은 수백만-수십억 이미지로 수년간 학습
- CLIP: 4억 개의 (이미지, 텍스트) 쌍으로 학습하여 이 격차를 해소
2. 핵심 발견
- 확장성: 8개 모델을 통해 거의 2차수 magnitude의 compute 스케일링 연구
- 전이 성능: compute의 매끄럽게 예측 가능한 함수
- 다양한 태스크: GPT처럼 OCR, 지리적 위치 인식, 행동 인식 등 다양한 태스크 수행
- 경쟁력: 30개 이상 기존 데이터셋에서 task-specific supervised 모델과 경쟁
3. 강건성(Robustness)
- Zero-shot CLIP 모델이 동등한 정확도의 supervised ImageNet 모델보다 훨씬 강건함
- supervised ImageNet 실전에서는 성능이 떨어짐..

2. Approach
2.1. Natural Language Supervision
핵심 아이디어: 자연어에 포함된 감독 신호로부터 지각(perception)을 학습
자연어 감독의 장점
1. 확장성(Scalability)
자연어 감독:
- 인터넷상의 방대한 텍스트에서 수동적으로 학습
- "기계학습 호환 형식"이 필요 없음
- 자연스럽게 생성되는 데이터 활용
2. 유연한 Zero-shot 전이
자연어 감독:
- 표현을 언어와 연결하여 학습
- 언어를 통해 새로운 개념을 즉시 이해 가능
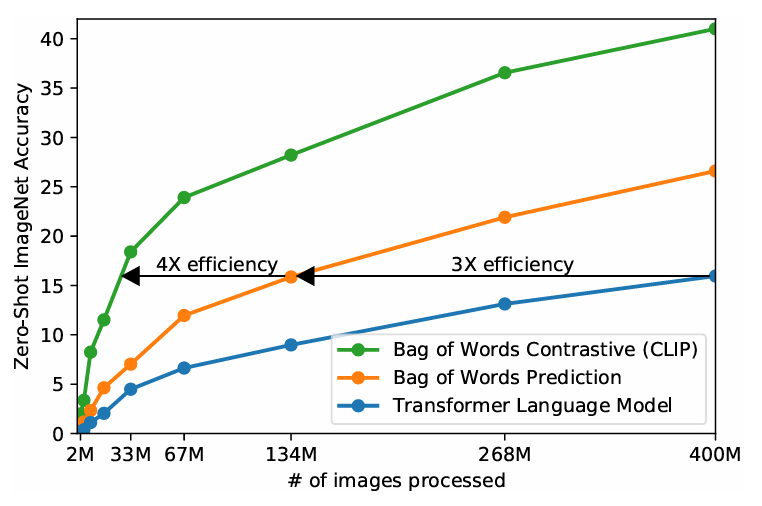
- Bag of Words Prediction: 전통적 방식
- Transformer Language Model: 더 복잡한 언어 모델
- Contrastive (CLIP): CLIP의 접근법
핵심!!!
기존 패러다임:
이미지 → 수동 라벨링 → 고정된 클래스 → 모델 학습
자연어 감독 패러다임:
- 단순히 크기만 큰 것이 아님
- 50만 개의 쿼리로 다양성 확보
- 쿼리당 균형 잡힌 샘플링으로 편향 방지
자연어 지도학습의 도전
- 개방형 시각 개념 집합을 학습해야 함
- 훨씬 더 복잡하고 다양한 태스크
- 효율성이 확장의 핵심
1단계: 초기 접근법 (VirTex 스타일)
2단계: Bag-of-Words 접근법
3단계: 대조 학습 (CLIP의 최종 선택)
이전 연구 대비 단순화된 부분들
- 사전 훈련된 가중치 없이 처음부터 학습
- 비선형 투영 제거: 선형 투영만 사용
- 텍스트 변환 함수 제거: 단일 문장 데이터가 많아서
- 단순한 이미지 변환: 랜덤 정사각형 크롭만 사용
- 온도 파라미터 직접 최적화: 하이퍼파라미터 튜닝 회피
단순화의 이유
- 대규모 데이터셋: 오버피팅 문제 없음
- 효율성 중심: 복잡한 기법보다 단순함이 더 효과적
이미지 인코더 아키텍처
1. ResNet-50 기반 인코더
기본 선택 이유:
- 널리 채택되고 검증된 성능
- 안정적인 베이스라인 제공
Attention Pooling으로 Global Average Pooling 대체
기존: Global Average Pooling → 단순 평균
개선: Transformer-style Multi-head QKV Attention
- Query: 이미지의 global average-pooled representation
- 더 정교한 특징 추출 가능
2. Vision Transformer (ViT) 기반 인코더
텍스트 처리 방식
입력 텍스트 → 소문자 변환 → BPE 인코딩 → Transformer 처리
특징 추출
→ Layer Normalization
→ Linear Projection
→ 멀티모달 임베딩 공간
설계 선택: Masked Self-Attention
- 사전 훈련된 언어 모델로 초기화 가능성 보존
- 언어 모델링을 보조 목표로 추가할 수 있는 유연성
- (향후 연구로 남겨둠)
CLIP의 ResNet 스케일링
EfficientNet 접근법 적용 (Tan & Le, 2019):
- 너비, 깊이, 해상도에 추가 계산량을 균등 배분
- 한 차원에만 집중하는 것보다 더 효과적
2.5. Training
모델들:
- ResNet 5개 (ResNet-50, 101 + 4배/16배/64배 스케일링 버전)
- Vision Transformer 3개 (ViT-B/32, B/16, L/14)
학습 설정:
- Adam 옵티마이저, 32 에폭, 배치 크기 32,768
- 메모리 절약을 위한 다양한 최적화 기법 사용
계산 규모:
- 최대 592개 V100 GPU로 18일간 학습
- 최종 최고 성능 모델: ViT-L/14@336px (고해상도 버전)
3. Experiments
3.1. Zero-Shot Transfer
- 기존: 보지 못한 객체 카테고리 분류
- CLIP: 보지 못한 데이터셋에 대한 일반화 → 태스크 학습 능력 측정
Visual N-Grams과의 비교했을 때 성능 개선
기존 데이터셋의 문제점:
- 다의어 문제: 같은 단어가 여러 의미 (예: "crane" - 건설장비 vs 새)
- 맥락 부족: 단순히 클래스 이름만 제공 (예: "boxer" - 개 품종 vs 운동선수)
- 분포 차이: 학습 데이터에서는 단일 단어보다 문장 형태가 많음
태스크별 맞춤 프롬프트:
- 애완동물: "A photo of a {label}, a type of pet."
- 음식: "A photo of a {label}, a type of food."
- 위성사진: "A satellite photo of a {label}."
- OCR: 텍스트 주변에 따옴표 추가
다양하게 넣는 것!!!!
앙상블도 효과적이었다
제로샷 vs 지도학습 성능 비교
27개 데이터셋 비교 결과:
- CLIP 제로샷이 ResNet-50 linear probe보다 16개 데이터셋에서 승리
- 특히 ImageNet에서도 제로샷이 더 좋은 성능
대부분 제로샷이 성능이 좋은데 제로샷의 약점 있긴 하다..
실패하는 태스크들:
- 위성 이미지 분류 (EuroSAT, RESISC45)
- 의료 이미지 (PatchCamelyon - 림프절 종양 검출)
- 객체 카운팅 (CLEVRCounts)
- 자율주행 관련 (GTSRB - 독일 교통표지, KITTI Distance)
전문적이고 복잡한 태스크에서는 여전히 한계가 있음
3.2. Representation Learning
CLIP의 광범위한 작업 수행 능력: 문서에 따르면 CLIP 모델은 단일 컴퓨터 비전 모델로서 이전에 입증된 것보다 훨씬 더 넓은 범위의 작업을 학습 가능
- 지리적 위치 파악(geo-localization)
- 광학 문자 인식(OCR)
- 얼굴 감정 인식
- 행동 인식
왜 이게 가능한가: 문서에서 언급하는 중요한 통찰은 ImageNet의 한계
예를 들어, ImageNet-1K는 모든 교통 표지판에 대해 단일 라벨만 가지고 있어서, 세밀한 구분이 어렵
반면 CLIP은 자연어 설명을 통해 더 풍부하고 세밀한 정보를 학습 가능
실제로는 "학습하지 않은" 것처럼 보이지만 언어를 통해 간접적으로 더 많은 정보를 습득한 것
즉, 제로샷이 "완전히 아무것도 모르는 상태"가 아니라, 언어적 이해를 통해 시각적 개념을 연결하는 능력
언어적 이해??
- 단어들 간의 수학적 관계 학습
- "고양이"와 "개"는 비슷한 벡터 공간에 위치
- "동물", "애완동물", "털"과 연관성 높음
- "자동차", "비행기"와는 거리가 멀음
- 텍스트-이미지 연결 패턴 학습
- "털이 있는 네 다리 동물" 텍스트 → 특정 이미지 특징들과 매칭
- "빨간 정지 표지판" 텍스트 → 빨간색 + 팔각형 + 'STOP' 글자 패턴
- 문맥적 조합 능력
- 개별 단어들을 조합해서 새로운 개념 이해
- "흰색 + 고양이 + 앉아있는" = 특정 시각적 패턴 예측
- 대량의 데이터에서 학습한 통계적 패턴을 통해 단어와 개념들 사이의 관계를 수학적으로 표현하고 활용하는 능력
3.3. Robustness to Natural Distribution Shift
CLIP의 놀라운 견고성
- 제로샷 CLIP은 분포 변화에서 훨씬 더 견고함
- ImageNet 정확도와 분포 변화 정확도 사이의 격차를 최대 75%까지 줄임
- 이는 제로샷 모델이 특정 분포에서만 성립하는 가짜 상관관계를 악용할 수 없기 때문
- 특정 데이터셋에서의 높은 성능 ≠ 실제 세계에서의 신뢰성
- 제로샷/Few-shot 접근법이 더 견고한 AI 시스템 개발에 핵심적
- 대규모 다양한 데이터셋에서의 사전 훈련이 중요
문서는 "진짜 AI의 능력은 새로운 상황에서 얼마나 잘 작동하는가"라는 관점에서
CLIP의 제로샷 능력이 단순한 편의성이 아니라 근본적인 견고성의 원천임을 보여줌
4. Comparison to Human Performance
중요한 시사점:
1. 샘플 효율성의 격차 인간은 단 하나의 예시로 22%나 향상되는 반면,
CLIP의 few-shot 학습은 이만큼 효율적 x
이는 인간이 사전 지식을 효과적으로 활용하기 때문
2. few-shot 학습에서 사전 지식을 제대로 통합하는 방법을 찾는 것이 중요한 개선 방향
3. 제로샷의 의미 재정립 CLIP의 제로샷 성능이 인간의 원샷 성능보다 훨씬 뛰어나다는 것 -->
CLIP이 이미 엄청난 양의 사전 지식을 가지고 있음을 의미
즉, "제로샷"이라고 하지만 실제로는 방대한 언어-시각 연결 지식을 활용하는 것
결론: 이 비교는 CLIP의 강점(방대한 사전 지식)과 약점(효율적인 few-shot 학습)을 명확히 보여줌
인간의 메타인지 능력과 효율적인 학습 능력을 AI에 통합하는 것이 다음 단계의 중요한 도전과제임을 시사
5. Data Overlap Analysis
왜 중복이 많아도 성능 향상이 적을까?
이 분석은 CLIP의 제로샷 성능이 데이터 유출(data leakage)에 의한 것이 아니라 진정한 일반화 능력임을 보여줌
중복이 존재하더라도 그 영향은 미미하며, 이는 이전 연구들(Mahajan et al., Kolesnikov et al.)과도 일치하는 결과
6. Limitations
성능 및 일반화 (Performance & Generalization)
- 표준 벤치마크에서의 평범한 성능: 많은 데이터셋에서 제로샷(zero-shot) CLIP의 성능은 ResNet-50 특징(feature) 위에 선형 분류기를 올린 단순한 베이스라인과 비슷한 수준이며, 전반적인 최신 기술(state-of-the-art)에는 크게 미치지 못함
- 세분화 및 추상적 작업에 대한 취약성: CLIP은 자동차 모델, 꽃 품종, 항공기 기종을 구별하는 것과 같은 세분화된 분류 작업에 취약 또한 이미지에 있는 객체의 수를 세는 것과 같은 추상적이거나 체계적인 작업, 그리고 훈련 데이터셋에 포함되지 않았을 새로운 작업(예: 사진에서 가장 가까운 차까지의 거리 분류)에서는 성능이 거의 무작위 수준에 가까움..
- 분포를 벗어난 데이터에 대한 낮은 일반화 성능: CLIP은 훈련 데이터의 분포에서 완전히 벗어난 데이터에 대해서는 일반화 성능이 떨어짐 대표적인 예로, 렌더링된 디지털 텍스트에서는 OCR 성능이 좋지만, MNIST 손글씨 숫자 데이터셋에서는 88%의 정확도밖에 달성하지 못하는데, 이는 훨씬 단순한 모델보다도 낮은 성능입니다. 이는 CLIP이 방대한 데이터셋으로 학습하여 문제를 회피할 뿐, 딥러닝 모델의 취약한 일반화라는 근본적인 문제를 해결하지 못했음을 시사
효율성 및 훈련 (Efficiency and Training)
- 높은 연산 비용: 제로샷 CLIP이 전반적인 최신 기술 수준의 성능에 도달하기 위해서는 약 1000배의 컴퓨팅 자원 증가가 필요할 것으로 추정되며, 이는 현재 하드웨어로는 실현 불가능
- 데이터 비효율성: CLIP은 딥러닝의 고질적인 문제인 데이터 비효율성을 해결하지 못함 대신 수억 개의 훈련 샘플을 사용할 수 있는 데이터 소스로 이를 보완 훈련 과정에서 본 모든 이미지를 초당 1장씩 본다면 405년이 걸릴 정도의 방대한 양
기능적 및 방법론적 제약 (Functional & Methodological Constraints)
- 주어진 개념 내에서만 선택 가능: CLIP은 주어진 분류기(classifier)에 포함된 개념들 중에서만 선택할 수 있다는 한계
새로운 결과물을 생성할 수 있는 이미지 캡셔닝과 같은 접근 방식에 비해 유연성이 떨어짐 - 개발 과정의 문제: 제로샷 전이를 목표로 했음에도 불구하고, CLIP 개발 과정에서 검증 데이터셋(validation sets)의 성능을 반복적으로 확인. 이는 진정한 제로샷 시나리오와는 거리가 멀며, 사용된 평가 데이터셋 자체가 CLIP의 개발 및 성능에 맞춰 편향되었을 가능성이 있음
- 사회적 편향: CLIP은 필터링되지 않고 정제되지 않은 인터넷의 이미지-텍스트 쌍으로 훈련 --> 데이터에 내재된 많은 사회적 편견을 학습
- 직접적인 퓨샷(Few-shot) 학습의 부재: CLIP은 소수의 예시를 통한 학습(few-shot learning)에 직접적으로 최적화되어 있지 않다. 이 때문에 제로샷에서 퓨샷 설정으로 전환할 때 오히려 성능이 직관과 반대로 떨어지는 현상이 발생
7. Broader Impacts
성별 편향 (Gender Bias), 인종 편향 (Racial Bias) 등 존재
