ViT: Vision Transformer
트랜스포머를 이미지Vision에 적용해보자!!
1 INTRODUCTION
트랜스포머의 셀프 어텐션 구조는 NLP 분야에서 높은 성과를 냄
With the models and datasets growing, there is still no sign of saturating performance.
컴퓨터 비전에서는 여전히 합성곱 위주의 계산이 지배적(dominant)
NLP 분야에서 영향을 받아 셀프 어텐션 구조를 적용해보고자 함
그런데 막상 해봤는데 ResNet이 성과가 더 좋았음
Therefore, in large-scale image recognition, classic ResNet like architectures are still state of the art.
트랜스포머 스케일링(모델을 크게 만드는 것)에 영감을 받고 수정 없이 이미지를 바로 넣는 것을 해보았다
이미지를 분할하고 그 분할된 이미지를 일종의 단어 토큰 취급하여 모델을 학습
To do so, we split an image into patches and provide the sequence of linear embeddings of these patches as an input to a Transformer.
Image patches are treated the same way as tokens (words) in an NLP application.
중간 크기의 데이터셋으로 했을 때는 여전히 ResNet이 성능이 좋았음
When trained on mid-sized datasets such as ImageNet without strong regularization, these models yield modest accuracies of a few percentage points below ResNets of comparable size.
트랜스포머는 inductive biases이 적기에 그런 것은 아닐까...
그런데 데이터 크기를 늘리니 성능이 좋아졌다!
We find that large scale training trumps inductive bias.
inductive bias란?
모델이 학습 전에 이미 가지고 있는 지식, 가정, 또는 구조적인 성향
Translation equivariance(예: 고양이가 어디에 있든 동일한 고양이로 인식함)
locality(예: 이미지 공간에서 특정 특징 주변에 유사한 특징이 존재함)라는 성질을 잘 반영
2 RELATED WORK
기존 트랜스포머 모델은 사전학습 -> 파인튜닝 이런 형태
트랜스포머 CNN에 적용하기?
global하게 적용하면 압도적 계산 증가
주변만 보는 셀프 어텐션 진행
applied the self-attention only in local neighborhoods for each query pixel instead of globally.
ViT는 기존 모델보다 성능 좋다
기존 모델은 small-resolution images 만 가능했는데 ViT는 medium-resolution images도 가능하다
Moreover, Cordonnier et al. (2020) use a small patch size of 2 2 pixels, which makes the model applicable only to small-resolution images, while we handle medium-resolution images as well.
3 METHOD
3.1 VISION TRANSFORMER (VIT)
원래 자연어 처리에서는 토큰을 1차원으로 받는다
벡터 형태로 받는 것
비전 트랜스포머도 같은 방식을 원한다...
그런데 이미지는 3차원 텐서이다 어쩌지?


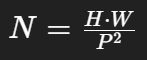
각 패치를 임베딩 토큰을 같은 크기 D 사이즈 벡터로 만든다 (왜냐하면 트랜스포머는 고정된 크기의 벡터가 필요하기 때문)
patch embedding 이라고 부름
BERT 모델의 [CLS] 토큰과 유사한 x_class 토큰이 있고, 모든 트랜스포머 레이어를 통과한 인코더의 아웃풋( z₀ᴸ)
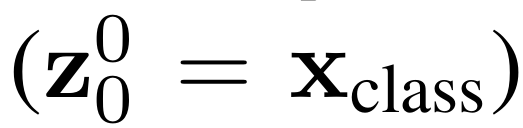
위치 정보도 중요하다 (그래야 이미지의 특징 파악을 더 잘하는 것!)
트랜스포머 자체에 내제된 위치 인식 기능이 없으니까 --> 위치를 매핑해준다
그런데 이때 2차원으로 나눠서 위치 매겨주었을 때 큰 효과 성능 x
그래서 그냥 벡터로 쭉 진행함
We use standard learnable 1D position embeddings, since we have not observed significant performance gains from using more advanced 2D-aware position embeddings.
활성화 함수로는 GELU 사용

(1)
CLS 같은 토큰과 각 이미지 패치들 + 위치 임배딩(pos)까지 한 것을 더한 것을 나타낸 식

(2)
잔차 연결 진행
이런 식으로 구성된 것 (MSA 멀티헤드 셀프 어텐션 (LN 레이어 정규화) ) + 첫번째 식에서 구한 것

(3)
두번째 식에서 구한 것을 가지고
MLP 로만 바꾸어 구하기 2-layer MLP (with GELU activation)
그리고 또 잔차 연결
(4)
0부터 L까지 해서 구한 것 바탕으로
LayerNorm 하고 마지막 아웃풋 출력하기!!
Inductive Bias
데이터 구조에 대해 모델 내부에 내장된 값(트레인이 시작되기도 전에!)
이 Inductive Bias 가 CNN에서는 강력하다
이미지 특성(2차원, 주변부와의 연관성, 위치 따라 결과값 다른 것 등) 적은 데이터로 파악하는데 유리
모델의 구조에 따라 정해진다.
그런데 비전 트랜스포머는 그것을 활용하기에 적절하지 못한 환경 ( 2차원 환경이 아니고.. 등등)
그래서 맨땅에서 공간 정보 학습해나가야 함
그래서 연구자들은 CNN과 트랜스포머를 합치면 어떨까라는 생각을 하게 됨
CNN 모델을 통해 얻은 피쳐 맵을 가지고 그것을 이미지 패치로 쪼갠다 (전에 했던 것처럼)
그것을 패치 임배딩에 적용하는 것
특수 경우: 1*1 이면 그냥 flattening 한다는 의미다
As a special case, the patches can have spatial size 1×1, which means that the input sequence is obtained by simply flattening the spatial dimensions of the feature map and projecting to the Transformer dimension.
3.2 FINE-TUNING AND HIGHER RESOLUTION
전이학습 진행
그때 pre-trained prediction head 을 지운다
그리고 zero-initialized D*K feedforward layer를 추가한다
D = hidden size, K = new classes K 는 새로운 데이터셋에서 온 것
사전 학습보다 파인튜닝은 더 높은 해상도로 하는 것이 이득이다
Bigger images = more detail → better accuracy
그런데 이때 픽셀 사이즈를 같게 하니까 시퀀스 길이는 계속 길어진다
사전학습이랑 파인튜닝 시 이미지 크기 다르니까 위치 임배딩은 효과적이지 않다
보간법으로 위치 임배딩을 resize 하자

4 EXPERIMENTS
4.1 SETUP
| Dataset | Classes | Images | Description |
| ImageNet-1k | 1,000 | 1.3M | Standard benchmark dataset |
| ImageNet-21k | ~21,000 | 14M | A much larger version of ImageNet |
| JFT | ~18,000 | 303M | Huge internal Google dataset (not public) |
ViT-B/16 → Base size, patch size 16×16
ViT-L/16 → Large size
ViT-H/14 → Huge size, patch size 14×14 (더 많은 패치 = 더 긴 시퀀스)
베이스라인 CNN:
ResNet
GroupNorm 사용 BatchNorm 대신에
표준화된 합성곱
Hybrid Models: CNN feature maps 을 ViT에 적용한 것
| 사전 학습 | Adam 옵티마이저 β1=0.9, β2=0.999 Batch size: 4096 |
| 파인 튜닝 | SGD with momentum Batch size: 512 |
평가지표는?
Fine-tuning Accuracy
pre-training된 모델의 전체 구조를 그대로 가져오고, 마지막 분류기(헤드)를 바꾸고 다시 전체를 학습
Few-shot Accuracy
사전학습된 모델의 표현 능력만 측정하기 위한 것
전체 모델을 freeze --> 적은 수의 레이블 예제로 간단한 선형 분류기(회귀식)만 학습
정답 라벨(y) 예측하는 선형 모델을 최소제곱법으로 푸는 방식 --> 해를 수식으로 바로 계산 가능 그래서 빠름
4.2 COMPARISON TO STATE OF THE ART
비교 대상 모델
| BiT | Big Transfer 대규모 ResNet 계열 CNN 모델을 사용하며 완전 지도학습(supervised learning) 방식으로 학습 주로 대용량 라벨링된 데이터셋으로 학습 |
| Noisy Student | EfficientNet-L2 기반 모델 반지도학습(semi-supervised learning) 방식 ImageNet 및 JFT-300M 데이터를 사용 JFT의 라벨(label)은 사용 x 현재 ImageNet 기준 SOTA 기록한 방식 중 하나 |

ViT-H/14 모델 최고 정확도 달성
BiT나 Noisy Student보다 훨씬 적은 연산 자원 사용!
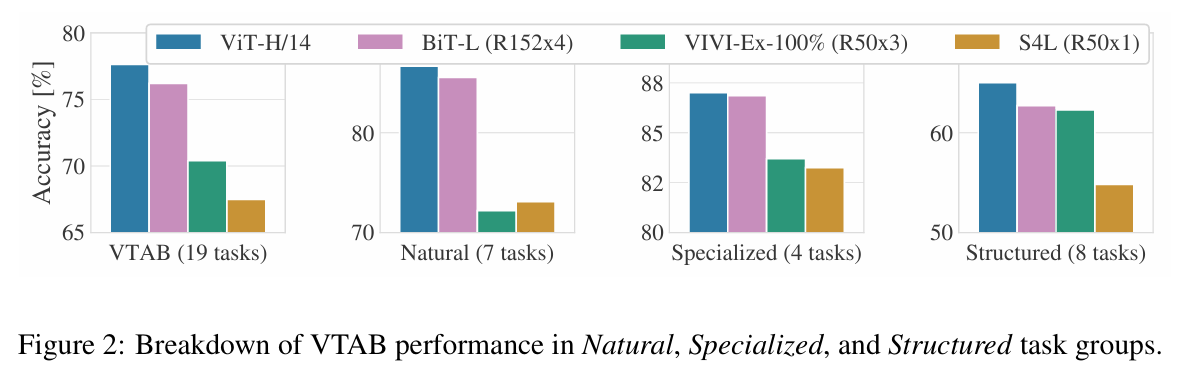
| Task 그룹 | 설명 | ViT-H/14 | BiT-L (R152x4) | VIVI-Ex-100% (R50x3) | S4L |
| VTAB 전체 (19개) | 모든 태스크 평균 | 최고 성능 | 약간 낮음 | 더 낮음 | 가장 낮음 |
| Natural (7개) | 자연 이미지 (CIFAR, Pets 등) | 최고 성능 | 약간 낮음 | 낮음 | 낮음 |
| Specialized (4개) | 의료 영상, 위성 사진 등 | 비슷하거나 약간 더 좋음 | 거의 동일 | 낮음 | 낮음 |
| Structured (8개) | 기하학/위치 정보 등 구조 추론 | 뚜렷한 우세 | 낮음 | 더 낮음 | 가장 낮음 |
4.3 PRE-TRAININGDATAREQUIREMENTS
ViT는 CNN보다 inductive bias(귀납적 편향)이 적은데, 성능을 내기 위해 얼마나 많은 데이터를 필요로 할까?
실험 1 – 사전 학습 데이터 크기 변화
실험 2 – JFT( Google이 자체적으로 구축한 초대규모 이미지 데이터셋)의 부분 집합 학습

Figure 3
큰 ViT 모델일수록 큰 데이터셋에서 진가 발휘
Figure 4
ResNet 작은 데이터 bb, 금방 성능이 한계치(plateau)에 도달
ViT 작은 데이터 과적합(overfit) → 큰 데이터 더 강력해짐
CNN은 작은 데이터 bb, ViT는 큰 데이터 bb
4.4 SCALING STUDY
모델 크기를 키우면 성능은 어떻게 변할까?
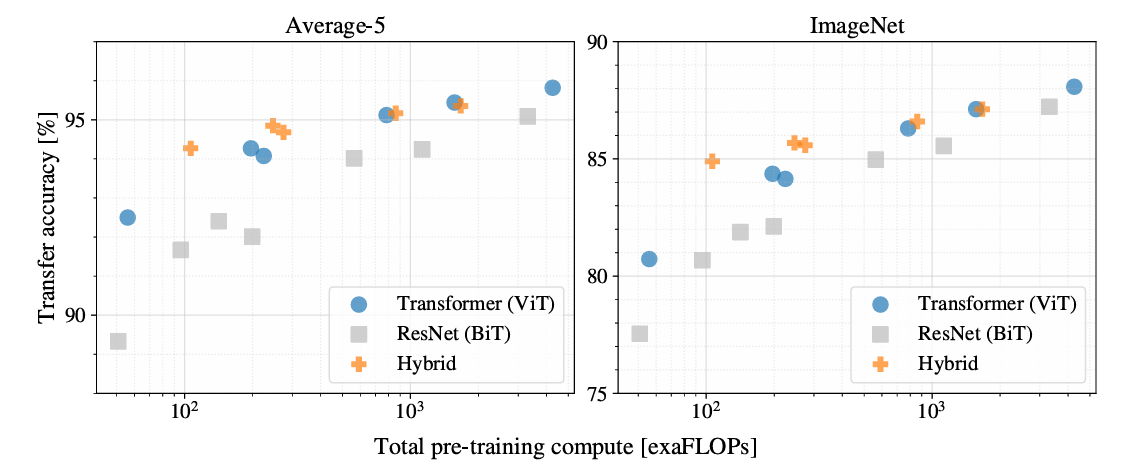
Figure 5
동일한 연산량 조건
ViT가 ResNet보다 더 나은 성능
소형 모델 Hybrid (CNN + Transformer) bb
대형 모델 순수 ViT bb
4.5 INSPECTING VISION TRANSFORMER
1. Patch 임베딩 분석
ViT의 첫 번째 레이어: 이미지 패치(조각) 선형 변환 --> 낮은 차원의 임베딩
2. 위치(Position) 임베딩
패치가 이미지 내 어디에 있는지 알려주는 벡터
가까운 위치 패치는 유사한 임베딩
행/열 구조도 나타남 (ex. 같은 행 또는 열에 있는 패치들은 더 유사)
--> ViT는 2D 이미지의 공간 구조를 임베딩 안에 자연스럽게 학습
3. Self-Attention 범위 분석 (Receptive Field처럼)
ViT는 Self-Attention -> 전 이미지 영역에 걸쳐 정보를 통합 가능
| 층 | 깊이 특징 |
| 초기층 | 일부 Attention Head는 이미 전체 이미지에 주목함 |
| 다른 Head | 매우 국소적인 주의만 사용 (작은 거리 내에서 정보 통합) |
| 깊은 층으로 갈수록 | Attention 범위가 넓어짐 (더 전역적 정보 사용) |
Hybrid 모델(ResNet + ViT) 초기 attention이 더 국소적
→ CNN의 초기층처럼 작동 (국소 정보 추출)
ViT는 클래스 예측 시 의미 있는 영역에 집중
→ Figure 6 클래스 토큰이 귀, 눈, 등 중요한 부분을 주로 바라봄

4.6 SELF-SUPERVISION 자기지도 학습
Transformer의 성공은 구조 또한 자기지도학습(SSL) 덕분
ViT에도 BERT 방식의 SSL을 실험!!
BERT 문장의 일부 단어를 가리고(Masked) 맞히는 식으로 사전학습
ViT에서도 이런 방식 가능??
결과... Self-supervised 방식 성능 향상 yes
but, 완전한 supervised 성능보다 4% 정도 낮음
5 CONCLUSION
Transformer 그대로 이미지 분류에 직접 적용
CNN처럼 이미지에 특화된 inductive bias(귀납적 편향) 을 넣지 x
다만 이미지를 패치로 나누는 단계만 적용 (이미지를 쪼개서 문장 토큰처럼 다루었다)
그랬더니..!!
대규모 데이터셋으로 사전학습(pre-training) 시 놀라운 성능
향후 과제
다른 컴퓨터 비전 작업으로의 확장 - 객체 인식 등
자기지도학습(Self-Supervised Learning)의 성능 개선
더 큰 규모로 확장