BART(Bidirectional and Auto-Regressive Transformers)
| 인코더 | 입력 이해 | Bidirectional (양방향) |
| 디코더 | 문장 생성 | Auto-Regressive (자동회귀적) |
Transformer 기반 모델
1 Introduction
Self-Supervised Learning의 진화
- masked language modeling(MLM) 기반의 모델(일부 단어를 가리고 복원하는 방식)
- 특정 작업(span prediction, generation 등)에만 강점을 보여 범용성이 떨어짐
BART의 제안
- Bidirectional + Auto-Regressive Transformer의 조합
- BERT의 인코더 + GPT의 디코더를 결합한 구조(sequence-to-sequence (seq2seq) 모델)
- 인코더: 입력 문장을 양방향으로 완벽히 이해해서, 문맥 정보를 풍부하게 얻음
- 디코더: 인코더가 이해한 정보를 바탕으로, 왼쪽에서 오른쪽으로 자연스럽게 문장을 생성함
- BART는 denoising autoencoder로, 두 단계로 사전학습
- 텍스트를 임의의 노이징 방식으로 훼손
- 시퀀스-투-시퀀스 모델을 사용해 원래 텍스트를 복원하도록 학습
- 핵심 특징 - 노이징 유연성
- 다양한 종류의 입력 왜곡 가능해서 학습의 일반화에 유리
- 예: 문장 순서 섞기, in-filling (마스킹된 부분의 길이는 가변적이고, 일부는 0개 단어 (즉, 삽입)일 수도 있음.)

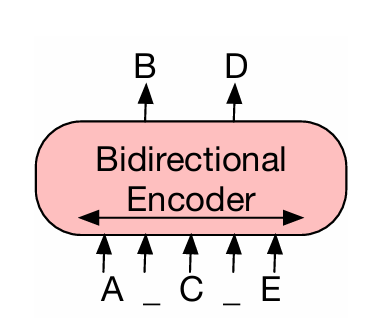


2 Model — BART의 구조와 학습 방식
BART
- denoising autoencoder
- 입력 훼손된(corrupted) 문서 --> 정상 문서로 복원
- sequence-to-sequence (seq2seq) 모델 구조를 사용
- 인코더는 훼손된 문장을 양방향으로 읽고 이해
- 디코더는 왼쪽에서 오른쪽으로 차례대로 문장을 생성해서 복원
- 학습 목표는 원래 문서가 나올 확률을 최대화하는 것 (negative log likelihood 최소화).
Pre-training — 사전학습 방식
- BART는 문서에 다양한 노이즈(훼손)를 적용한 후,
- 디코더가 원래 문서를 복원하도록 학습함.
- 재구성 손실(cross-entropy loss)을 최소화하는 방향으로 최적화
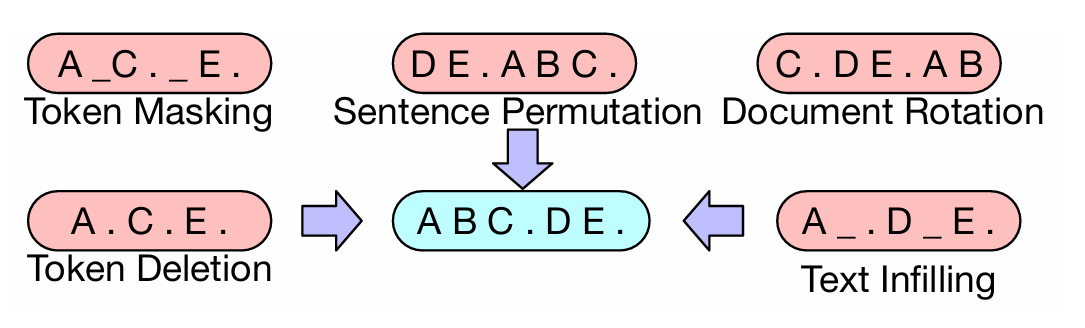
주요 노이징 기법
| Token Masking | BERT처럼 단어 일부를 [MASK]로 바꿈 | 단어 예측 능력 강화 |
| Token Deletion | 임의 단어를 삭제 | 모델이 어디가 빠졌는지 추론하게 함 |
| Text Infilling | 임의 길이 스팬(span)을 [MASK] 하나로 대체 | 스팬 복원 학습, 문맥 이해 강화 (SpanBERT에서 영감) |
| Sentence Permutation | 문장을 무작위 순서로 섞음 | 문장 순서 이해 및 복원 능력 강화 |
| Document Rotation | 문서 내 임의 위치에서 시작하도록 토큰 순서 변경 | 문서 시작점 인식 훈련 |
BART가 특별한 이유
- 임의로 여러 노이징을 조합해 적용할 수 있어 매우 유연
- 극단적으로 입력 정보가 모두 사라져도, BART는 그냥 언어모델로 작동할 수 있음.
- BART의 디코더는 GPT처럼 왼쪽에서 오른쪽으로 문장을 생성할 수 있는 언어모델
- 따라서 인코더가 아무것도 주지 않아도, 디코더는 스스로 언어를 생성 가능
- 이건 GPT와 동일한 능력이고, BERT는 못 하는 일
- 다양한 노이징 기법을 통해 문맥 이해와 문장 생성 능력을 모두 키움
3 Fine-tuning BART — BART의 미세 조정
| Task 유형 | BART 활용법 | 핵심 아이디어 |
| 문장 분류 (Sequence Classification) | 입력을 인코더/디코더 모두에 넣고, 디코더 마지막 토큰 표현 사용 | CLS 토큰과 유사, 디코더 끝에 특별 토큰 추가 |
| 토큰 분류 (Token Classification) | 입력 전체 → 인코더/디코더 → 각 토큰별 디코더 은닉 상태로 분류 | SQuAD 답변 위치 찾기 등에 활용 |
| 문장 생성 (Sequence Generation) | 자동회귀 디코더로 직접 미세 조정 가능 | 사전학습 목표와 유사, 생성 작업에 적합 |
| 기계 번역 (Machine Translation) | BART 전체를 디코더로 쓰고, 새 인코더 추가 후 두 단계 학습 | 사전학습된 BART 디코더 재활용, 새 인코더로 외국어 입력 변환 |
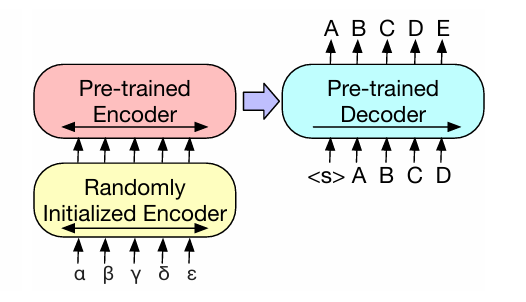
4 Comparing Pre-training Objectives
- 여러 사전학습 방식을 비슷한 조건(데이터, 크기, 학습 steps 등)에서 비교
그 중 언뜻봐서 이해가 쉽지 않은... 4, 5 번이름 설명 참고 논문 Language Model GPT처럼 왼쪽에서 오른쪽으로(Left-to-right) 토큰을 예측하는 모델 Radford et al., 2018 Permuted Language Model XLNet 방식으로 일부 토큰을 무작위 순서로 생성 Yang et al., 2019 Masked Language Model BERT 방식, 15% 토큰을 [MASK]로 바꾸고 예측 Devlin et al., 2019 Multitask Masked LM UniLM 방식, 다양한 self-attention 마스크 적용 Dong et al., 2019 Masked Seq-to-Seq MASS 방식, 입력의 50%를 마스킹 후 seq2seq로 복원 Song et al., 2019 - Multitask Masked Language Model (멀티태스크 마스크 LM)
- 핵심 아이디어
하나의 모델이 여러 종류의 언어 모델링 작업을 동시에 수행
self-attention 마스크(주의 마스크)를 적용해 모델이 여러 패턴을 학습
- Self-attention 마스크 종류
- 왼→오 (Left-to-right): 일반적인 언어 모델처럼, 현재 단어는 이전 단어들만 볼 수 있음.
- 오→왼 (Right-to-left): 역방향으로 단어들을 예측하는 방식.
- 전체 (Unmasked): 모든 단어를 볼 수 있는 완전한 양방향 상황.
- 부분 마스크 (First 50% unmasked + Left-to-right for remainder): 앞쪽 절반은 전체를 보고, 뒤쪽 절반은 왼→오로만 보는 혼합 형태.
- Self-attention 마스크 종류
- 핵심 아이디어
- asked Seq-to-Seq (MASS 방식)
- 문장에서 일정 구간(연속된 span) 마스킹
- sequence-to-sequence (인코더-디코더) 구조를 이용
- 마스킹된 부분을 복원하는 것을 목표로 학습
- Input to encoder: "The quick <MASK> <MASK> <MASK> the lazy dog"
- Target to predict: "brown fox jumps over"
따라서...
- BART의 text infilling + token deletion 방식이 다양한 작업에서 안정적으로 좋은 성능
- 단일 left-to-right language model이나 문장 순서 섞기 같은 방법은 특정 작업에서만 좋거나 성능이 떨어짐.
- BART는 양방향 인코더와 autoregressive 디코더를 활용해 범용적인 사전학습 목표를 달성함.
- 양방향 인코더 (Bidirectional Encoder)
→ 문장의 앞뒤를 모두 보며 의미를 인코딩함.
→ BERT처럼 문장 전체를 이해하는 데 유리함. - 오토리그레시브 디코더 (Autoregressive Decoder)
→ 하나씩 순서대로 단어를 생성하는 구조.
→ GPT처럼 자연스러운 문장 생성에 유리함. - 이 둘을 합쳐서 이해 + 생성을 모두 잘하는 모델을 만든 것이 BART
- 양방향 인코더 (Bidirectional Encoder)
5. 대규모 사전학습 실험 (Large-scale Pre-training Experiments)
| TASK | 성능 요약 |
| 분류 (GLUE, SQuAD) | RoBERTa와 유사한 성능 |
| 요약 (CNN/DM, XSum) | 기존 최고 성능 대비 최대 +6점 향상 |
| 대화 (CONVAI2) | F1 및 Perplexity 모두 최고 |
| 질문응답 (ELI5) | 자유형 QA에서도 최고 성능 |
| 번역 (RO→EN) | Back-Translation 기반 Transformer보다 우수 |
6. 정성적 분석 (Qualitative Analysis)
- BART는 요약 과제에서 큰 성능 향상을 보임
| 항목 | 평가 |
| 언어 유창성 | 매우 우수 (자연스러운 영어) |
| 추상성 수준 | 높음 (거의 복사 없이 재작성) |
| 사실 정확성 | 대체로 정확하나 일부 사실 왜곡/추론 오류 발생 |
| 추론 능력 | 강력함 (문맥 기반 연결과 배경지식 활용) |
7. 관련 연구 (Related Work)
- 기존 사전학습 방식:
- GPT: 왼쪽 문맥만 고려해 학습 → 일부 과제에는 한계.
- ELMo: 왼쪽/오른쪽 문맥 따로 학습 → 상호작용 부족.
- BERT: 마스크 언어 모델(Masked LM) 방식으로 양방향 문맥을 함께 고려함.
- 문장 생성에 BERT는 한계: 예측이 비자동 회귀적(non-autoregressive)이기 때문에 자연스러운 생성에는 불리함.
- UniLM vs. BART:
- UniLM: 마스킹 방식을 바꿔서 생성도 가능하지만 조건부 독립 방식이라 문맥 연결이 덜 자연스러움.
- BART: 자동 회귀 방식으로 생성 학습 → 실제 생성 시기와 일치함
자동 회귀 왼쪽부터 하나씩, 이전 단어들을 참고해서 다음 단어 예측 GPT, BART 디코더 조건부 독립 단어들을 동시에 예측하거나, 서로 영향을 주지 않고 생성 UniLM 생성 시 일부 모드
8. 결론 (Conclusions)
BART : 손상된(corrupted) 문서를 원래대로 복원하도록 사전 학습하는 디노이징(autoencoder) 방식의 모델
향후 연구 방향 : 특정 과제에 맞춰 손상 방식을 조정하는 등 새로운 pretraining 전략 탐색이 필요